Practical Fuzzing
Welcome to Practical fuzzing! This repository contains practical fuzzing guides for various techniques and applications of different fuzzers. As much as possible, the tutorials here try to cover all the necessary information to follow them without assuming prior knowledge.
Windows Kernel Fuzzing
We can use LibFuzzer to fuzz the Windows Kernel and Windows Kernel Drivers in a "dumb" or "closed-box" mode. This tutorial should be followed in the Windows Kernel Development virtual machine.
- Set Up Development Environment
- Clone and Build HEVD
- Install the Code Signing Certificate
- Create and Start the Driver Service
- Create a Fuzz Harness
- Compile the Fuzz Harness
- Run the Fuzz Harness
- Extend the Length Faster
Development Environment
This tutorial should be followed in the Windows Kernel Development virtual machine. Set up a virtual machine as described in that tutorial. Building and running HEVD on your host machine is not recommended, because the tutorial will guide you through crashing the kernel which will blue-screen the virtual machine (and would blue-screen your host machine if run on it directly).
Clone and Build HEVD
We will use HackSys Extreme Vulnerable Driver (HEVD) as our windows driver target.
We'll clone HEVD into our home directory and enter the EWDK build environment.
cd ~
git clone https://github.com/novafacing/HackSysExtremeVulnerableDriver -b windows-training
cd HackSysExtremeVulnerableDriver/Driver
W:\LaunchBuildEnv.cmd
Now, we can go ahead and build the driver:
cmake -S . -B build -DKITS_ROOT="W:\Program Files\Windows Kits\10"
cmake --build build --config Release
And exit our build environment:
exit
Back in PowerShell, check to make sure there is a release directory:
ls build/HEVD/Windows/
You should see:
Directory: C:\Users\user\HackSysExtremeVulnerableDriver\Driver\build\HEVD\Windows
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 12/20/2023 7:16 PM CMakeFiles
d----- 12/20/2023 7:16 PM HEVD.dir
d----- 12/20/2023 7:17 PM Release
-a---- 12/20/2023 7:16 PM 1073 cmake_install.cmake
-a---- 12/20/2023 7:17 PM 2275 hevd.cat
-a---- 12/20/2023 7:17 PM 1456 HEVD.inf
-a---- 12/20/2023 7:17 PM 32216 HEVD.sys
-a---- 12/20/2023 7:16 PM 45308 HEVD.vcxproj
-a---- 12/20/2023 7:16 PM 4117 HEVD.vcxproj.filters
If so, we're in business!
Install the Code Signing Certificate
Windows does not permit loading drivers signed with untrusted certificates,
so we need to both import our untrusted certificate and enable test
signing. From the HackSysExtremeVulnerableDriver\Driver directory, run the following to enable test signing and reboot (which is required after enabling test signing):
certutil -importPFX HEVD\Windows\HEVD.pfx
bcdedit -set TESTSIGNING on
bcdedit -set loadoptions DISABLE_INTEGRITY_CHECKS
shutdown /r /f /t 0
Once the Virtual Machine reboots, you can reconnect with ssh -p 2222 user@localhost.
Create and Start the Driver Service
We'll create a service for the driver and start it.
sc.exe create HEVD type= kernel binPath= C:\Users\user\HackSysExtremeVulnerableDriver\Driver\build\HEVD\Windows\HEVD.sys
sc.exe start HEVD
You should see:
SERVICE_NAME: HEVD
TYPE : 1 KERNEL_DRIVER
STATE : 4 RUNNING
(STOPPABLE, NOT_PAUSABLE, IGNORES_SHUTDOWN)
WIN32_EXIT_CODE : 0 (0x0)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x0
WAIT_HINT : 0x0
PID : 0
FLAGS :
This means our vulnerable driver is now running.
Create a Fuzz Harness
We'll create a directory ~/fuzzer where we'll create and run our fuzz harness:
mkdir ~/fuzzer
cd ~/fuzzer
We're going to use LibFuzzer to fuzz the driver via its IOCTL interface. The handler for the interface is defined here.
Essentially, if we pass more than 512 * 4 = 2048 bytes of data, we will begin to
overflow the stack buffer. Create fuzzer.c by running vim fuzzer.c.
We'll start by including windows.h for the Windows API and stdio.h so we can print.
#include <windows.h>
#include <stdio.h>
Next, we need to define the control
code
for the driver interface. The device servicing IOCTL we are triggering is not a
pre-specified file
type,
so we access it with an unknown type. We grab the control code for the handler we want
from the driver source
code.
Note that in the handler, we can see this is a type 3 IOCTL handler (AKA
METHOD_NEITHER) and that we want RW access to the driver file.
#define HACKSYS_EVD_IOCTL_STACK_OVERFLOW CTL_CODE(FILE_DEVICE_UNKNOWN, 0x800, METHOD_NEITHER, FILE_ANY_ACCESS)
Next, we'll define our device name, a handle for the device once we open it, and a
global flag to check whether the device is initialized/opened. We could have also used
the Startup initialization
interface to LibFuzzer, but since we don't really need access to argv, we follow the
guidance to use a statically initialized global object.
const char g_devname[] = "\\\\.\\HackSysExtremeVulnerableDriver";
HANDLE g_device = INVALID_HANDLE_VALUE;
BOOL g_device_initialized = FALSE;
Now we can declare our fuzz driver. Since we're compiling as C code, note we do not
declare the function as extern "C", but if we were compiling as C++ we would need to
do this.
int LLVMFuzzerTestOneInput(const BYTE *data, size_t size) {
This function will be called in a loop with new inputs each time by the fuzz driver.
The first thing we need to do is check if the device handle is initialized, and initialize it if not.
if (!g_device_initialized) {
printf("Initializing device\n");
if ((g_device = CreateFileA(g_devname,
GENERIC_READ | GENERIC_WRITE,
0,
NULL,
OPEN_EXISTING,
0,
NULL
)) == INVALID_HANDLE_VALUE) {
printf("Failed to initialize device\n");
return -1;
}
printf("Initialized device\n");
g_device_initialized = TRUE;
}
Returning -1 from LLVMFuzzerTestOneInput indicates a bad input, but we will also
use it here to indicate an initialization error.
We'll also add a print for ourselves to let us know if the buffer should be overflowed by an input.
if (size > 2048) {
printf("Overflowing buffer!\n");
}
Finally, we'll call DeviceIoControl to interact with the driver by passing our input
data to the IOCTL interface.
DWORD size_returned = 0;
BOOL is_ok = DeviceIoControl(g_device,
HACKSYS_EVD_IOCTL_STACK_OVERFLOW,
(BYTE *)data,
(DWORD)size,
NULL, //outBuffer -> None
0, //outBuffer size -> 0
&size_returned,
NULL
);
if (!is_ok) {
printf("Error in DeviceIoControl\n");
return -1;
}
return 0;
}
Compile the Fuzz Harness
That's all we need to test the driver from user-space. We can now compile the harness by entering the Build Environment for VS Community (not the EWDK, because it lacks SanitizerCoverage and LibFuzzer):
& 'C:\Program Files\Microsoft Visual Studio\2022\Community\Common7\Tools\Launch-VsDevShell.ps1' -Arch amd64
cl /fsanitize=fuzzer /fsanitize-coverage=edge /fsanitize-coverage=trace-cmp /fsanitize-coverage=trace-div fuzzer.c
Run the Fuzz Harness
Now we just run:
./fuzzer.exe
And start testing the driver! The first thing we'll see is that it runs really quite fast, which is great. If we let the fuzzer run long enough, it'll eventually decide to generate an input that overflows the buffer, but it may take some time because we currently have no feedback from the driver we're testing -- only from the fuzzer program itself. This is "dumb fuzzing" at its finest, and we'll walk through the various options to improve the situation, starting with the easiest.
Extend the Length Faster
If we run our binary with -help=1, LibFuzzer will helpfully inform us of all the
different options to pass to the fuzzer to control its behavior.
./fuzzer.exe -help=1
The first thing we can adjust is the len_control option. Let's try setting it to 0,
which will tell the fuzzer not to wait before extending the input to be very long.
./fuzzer.exe -len_control=0
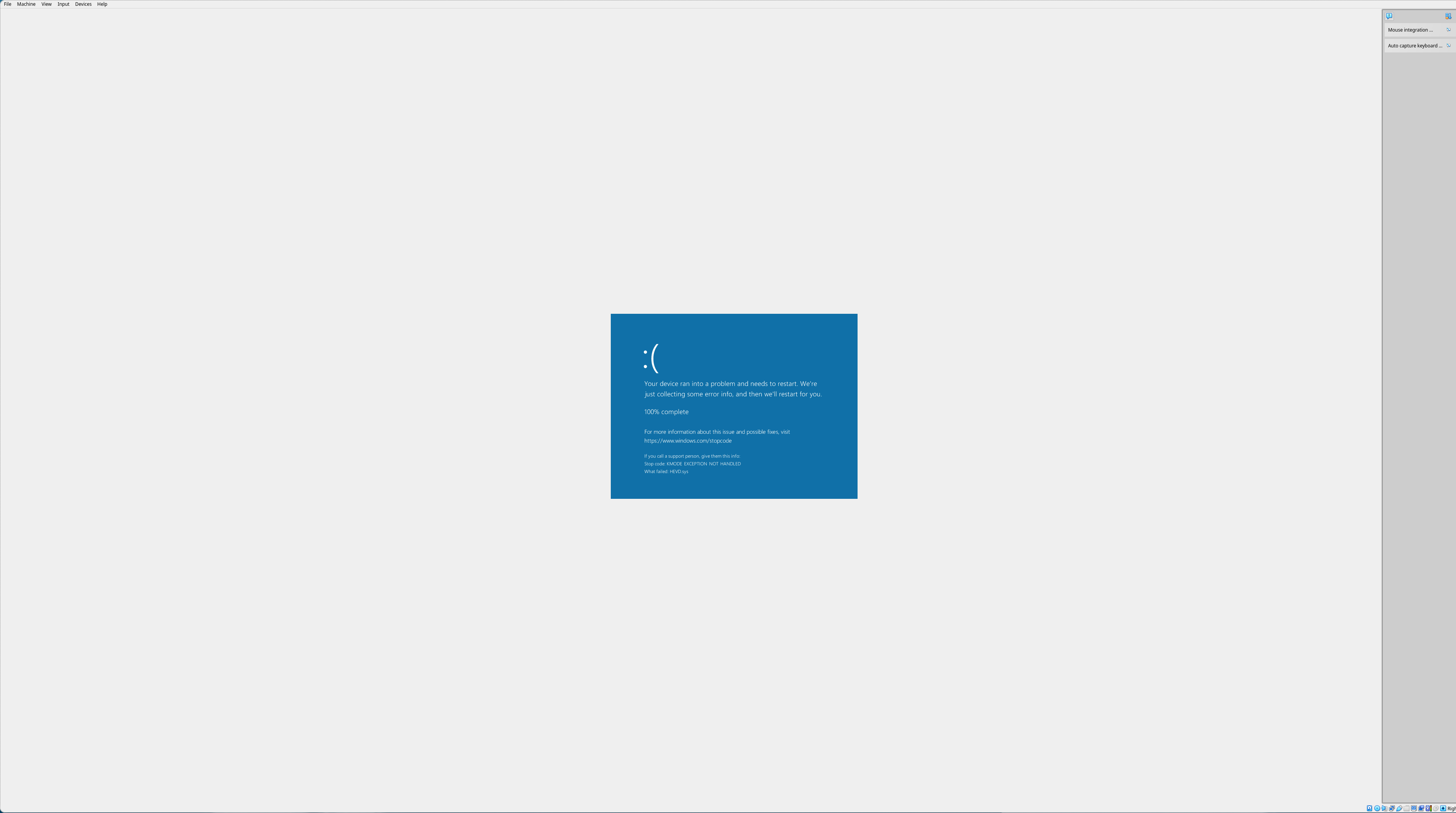
Boop! That did it. In many cases, this is all you need to discover trivial buffer overflows.
Linux Kernel Fuzzing
Introduction
So, you want to learn how to use LibAFL! Welcome to the future of fuzzing. You can read all about LibAFL and the features it offers on their github page, but the highlights are:
- Fast: LibAFL lets you create the fastest fuzzers possible, with minimal overhead.
- Rust: Take advantage of the Rust language and ecosystem, including package management and robust FFI.
- Scaling: LibAFL scales across cores and machines by default.
- Any platform: LibAFL runs on Windows, Linux, Android, MacOS, and embedded environments.
- Any target: LibAFL can fuzz targets on any platform it runs on, and any other platform by creating remote harnesses. Fuzz FPGAs, UEFI firmware, Web Apps, and more, with or without source code.
- Customizable: LibAFL gives you robust building blocks to assemble powerful fuzzers, but every component can be swapped out and customized for your use case or for maximum performance.
Some additional excellent resources on LibAFL are below.
Rust Quick-Start
This guide will get you started on some backgroundRust concepts you need to know to start in on the LibAFL tutorial.
There are many excellent Rust resources, some can be found below on various topics.
- Learn X in Y Minutes: Rust
- The Rust Programming Language
- The Rustonomicon: Unsafe Rust
- Rust Standard Library Documentation
- Cargo (Rust Package Manager) Book
- Rust By Example
- Rustlings: Rust Exercises
Fuzzing Rust
- Create The Crate
- Change The Crate Lib Type
- Add LibAFL-Targets Crate as a Dependency
- Features
- Choosing Good Fuzz Targets
- Creating our Fuzz Target
- Ownership and Moves
- Borrowing Mutably and Immutably
- Slices
- More Resources
- Implement the Fuzz Target
- Allocate Some Memory
- Decode Encoded Input
if letBindings- Ranges
- Test the Fuzz Target
- Analyzing the Bug
- Summary
- Create The Fuzzer Crate
- Add the LibAFL Crate as a Dependency
- Add LibAFL-Targets Crate as a Dependency
- Add the Target Crate as a Dependency
- Add Additional Dependencies
- Create a Build Script
- Coverage Sanitizer
- The Build Script
- Delete The Template
main.rs - Set The Global Allocator
- Import Coverage Observer
- Declare Functions From Target
- Add An Argument Parser
- Derive Macros
cargo buildcargo run- Add a Harness
- Closures
- Create A Harness Closure
- Add Observers and Feedbacks
- Observers
- Feedbacks
- Add Our Observers and Feedbacks
- Add Random Provider, Corpus, Solution Corpus, and State
- Random Provider
- Corpus
- Solution Corpus
- State
- Add Monitor, Event Manager, Scheduler, and Fuzzer
- Monitor
- Event Manager
- Scheduler
- Fuzzer
- Add Executor, Mutator, and Stages
- Executor
- Mutator
- Stages
- Load the Input Corpus
- Start The Fuzz Loop
- Run The Fuzzer
- Add A Corpus Entry
- Launch the Fuzzer
- Triage The Crash
- Summary
Create The Crate
Create the crate and enter the directory for our first fuzzer with:
$ cargo new --lib first-target
$ cd first-target
You should have a template Library crate as we saw in the Rust
Basics. To make sure everything is working
correctly, we'll run the tests cargo gives us
$ cargo test
Finished test [unoptimized + debuginfo] target(s) in 0.13s
Running unittests src/lib.rs (target/debug/deps/first_target-d654f36012dfaf5d)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests first-target
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
If you see that, we're ready to go!
Change The Crate Lib Type
Before we move on, we need to change the crate type of our fuzz target's crate. Rust's
build system supports many crate types, which you can read more about
here
. Add these two lines to your Cargo.toml file:
[lib]
crate-type = ["staticlib"]
For most normal rust libraries or crates, this is not necessary. However because we will be instrumenting this library for coverage feedback, we will need to build it separately and link it into our fuzzer. We'll discuss this further in the fuzzer section.
After changing the crate type, run cargo build and cargo test again to be sure
everything is still working as expected.
Add LibAFL-Targets Crate as a Dependency
The libafl_targets crate provides target-specific functionality and runtimes for
various instrumentation mechanisms designed to be used with libafl. In our case, it
provides an easy way to interact with SanitizerCoverage. We'll go in depth on our
instrumentation later, for now we'll just add the crate to our
Cargo.toml:
libafl_targets = { version = "0.11.2", features = [
"sancov_8bit",
"observers",
] }
Features
libafl_targets (and for that matter, most Rust crates) uses features to
conditionally compile parts of its functionality. For our uses, we need the feature
sancov_8bit because we'll be using 8-bit counter mode for SanitizerCoverage. We also
need the feature observers because we will be using a structure only defined with this
feature flag. You can read about features
here.
Choosing Good Fuzz Targets
The first thing we need to do when we're building a fuzzer is to identify what we want to fuzz. What makes a good fuzz target is complicated, and there are many factors to consider. In general, though, here are a few guidelines to keep an eye out for:
- Code that consumes untrusted data: any code that reads data from the outside world,
especially if the data comes from an untrusted source (i.e. comes from a user of your
code) is a great place to use fuzzing. Fuzzing can help find security issues with how
your code processes this data, as well as functionality and logic issues, especially
if your project includes assertions. Code patterns that commonly fit this criteria
include:
- Parsers, like those for web forms or API requests in JSON or similar formats
- OS or Library API functionality, for example when adding a system call to Linux or exporting any function from a library
- Command line tools that take input
- Update utilities that download update files from the internet
- Code that is security critical or runs with elevated privilege: if your code runs as
root or below (or an equivalent), it should be fuzzed. Even a single off-by-one error
in a
memcpycall is a critical security vulnerability in this scenario, as it gives way to privilege escalation. If your code is in this category, all of it should be fuzzed, not just external interfaces. We'll discuss later on some methods to speed up harnessing in this type of scenario.
Some additional resources for identifying good fuzz targets:
Creating our Fuzz Target
For our fuzz target, we'll assume we're writing some sort of internet accessible service and that the function we create takes some untrusted data. That means it would falls into category 1 above. We will create our fuzz target in Rust, and we are going to put a bug in it intentionally for the sake of demonstration.
In your lib.rs file, we'll first delete the all the contents cargo gave us, and
create a new function. Our fuzz target will be a decoder for a simple encoding format.
Add this (functionally incomplete, but we'll fill in the body later) definition for our
decode function:
#![allow(unused)] fn main() { pub fn decode(mut encoded_input: &[u8]) -> Vec<u8> { Vec::new() } }
This is a pub function (that is, it is exported) that takes a slice of encoded bytes
and returns a result (either a value or an error) where the value is a vector of
decoded bytes. Before we actually implement it, we need to learn a few concepts to
understand its parameter and return type.
This function takes a slice of unsigned 8-bit bytes. A slice is a reference to a
sequence of values of the same type (in this case u8) of some length. To understand
what a slice is, we need to understand the basics of references, ownership, and
borrowing.
Ownership and Moves
In Rust, all values have an owner. To check out ownership in action, we can create a
String variable using a let binding (the keyword for a statement to create a
variable in the current scope). Notice that we call .to_string() to convert the string
literal (a &str) into a String, although we'll avoid discussing that until a bit
later on.
fn main() { let _x: String = "Hello, World!".to_string(); }
We then own the value _x. In Rust, there can only be one owner of a variable at a
time, so if we call a function that takes a String as a parameter and prints it out.
Notice that println! is a variadic macro, and formats instances of {} in its first
argument with its remaining arguments, similar to printf in C, although using curly
braces instead of % symbols.
fn foo(bar: String) { println!("Got {}", bar); } fn main() { let x: String = "Hello, World!".to_string(); foo(x); }
We will move, or transfer ownership, of x to foo when we pass x to it as a
parameter. If we then want to use the value x later in the main function, for
example to print it out:
fn foo(bar: String) { println!("Got {}", bar); } fn main() { let x: String = "Hello, World!".to_string(); foo(x); println!("X is {}", x); }
You'll notice if you build or run this code in the Playground, we get a compile error:
Compiling playground v0.0.1 (/playground)
error[E0382]: borrow of moved value: `x`
--> src/main.rs:8:25
|
6 | let x: String = "Hello, World!".to_string();
| - move occurs because `x` has type `String`, which does not implement the `Copy` trait
7 | foo(x);
| - value moved here
8 | println!("X is {}", x);
| ^ value borrowed here after move
|
note: consider changing this parameter type in function `foo` to borrow instead if owning the value isn't necessary
--> src/main.rs:1:13
|
1 | fn foo(bar: String) {
| --- ^^^^^^ this parameter takes ownership of the value
| |
| in this function
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
7 | foo(x.clone());
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `playground` due to previous error
The error breaks down exactly what is happening here. main owned x when it was
declared, but it transferred ownership of x to foo when it passed x to foo as a
parameter. This means that when we try to use x in the println! statement we just
added to main, main actually no longer owns x, so it is an error to try and use
it!
This relationship is the core of how Rust ensures its safety guarantees, but may be
surprising to experienced C/C++ programmers because those languages have no enforced
concept of ownership of variables at all. There are a few ways to resolve this. The
first is to do what the compiler suggests, and clone() the string. This creates a
duplicate of the string in memory, and passes that duplicate to foo. This way, main
retains ownership of x, and foo gets its own duplicate as a parameter. These are
two different values, of course, but we are not modifying them so this is semantically
equivalent.
fn foo(bar: String) { println!("Got {}", bar); } fn main() { let x: String = "Hello, World!".to_string(); foo(x.clone()); println!("X is {}", x); }
If we run this, it'll succeed! However, we have made two tradeoffs. First, clone()
isn't free, either in terms of memory space or compute cycles. Second, if we added code
that modifies x in foo, main wouldn't print that modified value, it would print
the initial value. In this example, note that we have added the mut keyword to the
bar parameter in foo. This means this variable is mutable, so we can change it. If
we didn't add mut, it would be a compile error to modify the value of bar in this
function.
fn foo(mut bar: String) { bar += " I'm here!"; println!("Got {}", bar); } fn main() { let x: String = "Hello, World!".to_string(); foo(x.clone()); println!("X is {}", x); }
If we run this program in the Playground now, we'll see:
Got Hello, World! I'm here!
X is Hello, World!
This is, semantically, what we expect. foo modified its duplicate of x and printed
out the duplicate, while main printed out the original value. But what if we wanted
foo to modify the original value, instead? In C/C++, we'd pass a pointer to x to
foo if we wanted to do that. Rust has a similar concept called a reference, and the
act of creating a reference is called borrowing.
Borrowing Mutably and Immutably
A reference is denoted with the & symbol, so a String is the actual string instance,
while an &String is a reference to the string instance. Like variables, references
can be mutable or immutable, and mutable references are written &mut. These are also
sometimes called mutable borrows, because borrow and reference are used somewhat
interchangeably in Rust literature.
We'll change our foo function to take a mutable reference to a String instead of
taking ownership of its parameter. This has another side effect of making the clone()
call unnecessary. Because we are passing a reference as a parameter, we need to
dereference the variable in order to modify it. We also need to change how we pass in
the parameter to foo. Instead of just passing x, which is the variable x, we want
to pass a mutable reference to x, so we write &mut x. println! doesn't need us to
dereference x for it, because a &String, &mut String, and String can all be
Display-ed with the same code.
fn foo(bar: &mut String) { *bar += " I'm here!"; println!("Got {}", bar); } fn main() { let mut x: String = "Hello, World!".to_string(); foo(&mut x); println!("X is {}", x); }
We can run this now in the Playground and see that we print out the modified message both times:
Got Hello, World! I'm here!
X is Hello, World! I'm here!
Hopefully you have a rough understanding of what it means to own, reference, borrow,
and dereference in Rust. Remember up above when we brushed
past using .to_string() to convert a &str to a String? The .to_string() method
is implemented for str references and returns a String!
Slices
We just need one more concept before we're ready to move on with our fuzz target: slices!
A slice is just a reference to a sequence of items with the same type. They can be created literally, as with this creation of a slice referencing the sequence of two strings:
fn main() { let _x: &[String] = &[ "Hello, World!".to_string(), "I'm here!".to_string() ]; }
They can also be created by referencing another data structure. For example a slice of a
Vec (equivalent to a C++ std::vector) is a reference to a sequence of its entries.
We can also take a slice of a String's characters as a sequence of bytes using
.as_bytes(). Slices are very flexible, and many methods of various types yield slices
of different underlying element types (such as as_bytes()).
fn main() { let v: Vec<String> = vec![ "Hello, World!".to_string(), "I'm here!".to_string() ]; let _x: &[String] = &v; let u: String = "Hello, World!".to_string(); let _y: &[u8] = u.as_bytes(); }
More Resources
These Rust language topics are complex and nuanced, so you should be sure to read Understanding Ownership from the Rust documentation to understand them more deeply.
Implement the Fuzz Target
Now that we know what a slice is, we can implement our function. Remember our
function skeleton from our lib.rs:
#![allow(unused)] fn main() { pub fn decode(mut encoded_input: &[u8]) -> Vec<u8> { Vec::new() } }
We'll implement a simple decoder for URL-encoded text. URL-encoding looks something like
This%20string%20is%20URL%20encoded. We want to have a bug in this program that causes
it to crash, so we will use a bit of unsafe Rust. You can read all about unsafe Rust
here but basically the
unsafe keyword lets you:
- Dereference a raw pointer
- Call an unsafe function or method
- Access or modify a mutable static variable
- Implement an unsafe trait
- Access fields of unions
We'll use it to program like we're writing C/C++. You don't need to do this (there's a perfectly good safe implementation of URL decoding), we're just doing it for an example of a fuzz target that will actually crash.
Allocate Some Memory
We need to allocate some memory to store our decoded data. Here's where our bug will
live. We'll naively assume that because a % followed by two characters decodes to the
byte with the hex value of those two characters, that we can count up the % signs,
multiply it by 2, then subtract that count from the length of the input bytes to get the
decoded size. This is a bug because %% is a special case: it simply escapes the % and
decodes to one %. Thus, aa% would calculate a buffer length of 1, but we actually
need 2 bytes of space to store the decoded string.
#![allow(unused)] fn main() { use std::{ alloc::{alloc, Layout}, str::from_utf8_unchecked, }; const DEFAULT_BUFFER_SIZE: usize = 128; pub fn decode(encoded_input: &[u8]) -> Vec<u8> { let decoded_len = DEFAULT_BUFFER_SIZE + encoded_input.len() - (encoded_input.iter().filter(|c| **c == b'%').count() * 2); if decoded_len <= 0 { return Vec::new(); } let decoded_layout = Layout::array::<u8>(decoded_len).expect("Could not create layout"); let decoded = unsafe { alloc(decoded_layout) }; let mut decoded_ptr = decoded; Vec::new() } }
There are a few things going on here. We'll go step by step. First, we filter our
encoded input for '%' characters and count them, then subtract double that count from
the length of the encoded input to find the length of the decoded data. We'll also add a
constant 128 to our buffer size, to make our fuzzer at least do a little bit of work
to find this bug.Remember, this is an intentional bug because of various nuances in
the decoding process.
Next, we create a Layout (a description of an element size and length of an array of
u8s) of the length we just calculated. Notice the syntax of the Layout constructor
contains a turbofish (::<>), which is the syntax Rust uses for generic parameters.
Rust's generics are somewhat similar to C++, where if we wanted to construct a Layout
of an array of u32s instead, we would write Layout::array::<u8>(decoded_len). We'll
dive further into generic parameters later in these exercises, and you can read about
them here.
The .expect() function makes sure that a Result<T, E> is Ok(T) or that an
Option<T> is Some(T). If not, it will panic (or abort) with the message in the
call to .expect().
Finally, we have an unsafe block with a call to alloc(). This performs the
allocation for the decoded data. This is unsafe, because an alloc call with a
zero-sized layout is undefined behavior. Thus, this allocation in our code is actually
safe because we already checked to make sure the size is positive and non-zero. This
is a good reminder that unsafe in Rust does not mean the code is actually unsafe to
run, it only means that it is allowed to violate Rust's safety guarantees. We save the
pointer to the beginning of our decoded data (decoded) and duplicate the pointer to
(decoded_ptr) that we will use to write into our allocated memory.
Decode Encoded Input
Now, we'll do our actual decoding and write the decoded data into our pointer.
#![allow(unused)] fn main() { use std::{ alloc::{alloc, Layout}, str::from_utf8_unchecked, }; pub fn decode(mut encoded_input: &[u8]) -> Vec<u8> { /* ... Code from above ... */ loop { let mut parts = encoded_input.splitn(2, |&c| c == b'%'); let not_escaped_part = parts.next().expect("Did not get any unescaped data"); let rest = parts.next(); }
The first line here, loop { is a loop statement, which will run the block inside the
loop forever, until either a break or return happens.
Each time we run our loop, we split our encoded input on the first '%' character,
splitting it into at most 2 parts (hence splitn). The first part is any data at the
beginning of the encoded input before the first '%', the second part is the rest of the
encoded input after the first '%', if there is any. parts is an iterator over
sub-slices of type &[u8].
Iterators over an Item type (in this case, &[u8]) are types that have a next()
function to return the next Item if there is one, and None if there are no more
items (using an Option type, with the same semantics as Python's Optional[] and
C++'s std::option). Rust's iterators are extremely similar to Python's, and somewhat
similar to C++'s in theory (they both allow you to iterate over entries of some
collection), although not in implementation.
#![allow(unused)] fn main() { if rest.is_none() && decoded == decoded_ptr { return encoded_input.to_vec(); } else { }
Next, we check to see if we have anything in rest. If not, the % was at the end of
the input, or there was no '%'. If this is the case and we haven't written any decoded
data to our output, we can return the encoded input as the result, converting the slice
to a Vec (which performs an allocation).
#![allow(unused)] fn main() { for not_escaped_byte in not_escaped_part { unsafe { *decoded_ptr = *not_escaped_byte }; unsafe { decoded_ptr = decoded_ptr.add(1) }; } }
If we didn't return early, we always write our "not escaped" data to our output. This
operation is exactly equivalent to *ptr = b; ptr++; in C, we simply need to wrap this
operation in unsafe, because we are dereferencing a raw pointer. ++ and += are
also not defined on raw pointers, but we can use the .add() method, which is
#![allow(unused)] fn main() { if let Some(rest) = rest { if let Some(&[first, second]) = rest.get(0..2) { if let Ok(first_val) = u8::from_str_radix(unsafe { from_utf8_unchecked(&[first]) }, 16) { if let Ok(second_val) = u8::from_str_radix(unsafe { from_utf8_unchecked(&[second]) }, 16) { unsafe { *decoded_ptr = (first_val << 4) | second_val }; unsafe { decoded_ptr = decoded_ptr.add(1) }; encoded_input = &rest[2..]; } else { unsafe { *decoded_ptr = b'%' }; unsafe { decoded_ptr = decoded_ptr.add(1) }; unsafe { *decoded_ptr = first }; unsafe { decoded_ptr = decoded_ptr.add(1) }; encoded_input = &rest[1..]; } } else { unsafe { *decoded_ptr = b'%' }; unsafe { decoded_ptr = decoded_ptr.add(1) }; encoded_input = rest; } } else { unsafe { *decoded_ptr = b'%' }; unsafe { decoded_ptr = decoded_ptr.add(1) }; for rest_byte in rest { unsafe { *decoded_ptr = *rest_byte }; unsafe { decoded_ptr = decoded_ptr.add(1) }; } break; } } else { break; } } } unsafe { Vec::from_raw_parts(decoded, decoded_len, decoded_len) } } }
The rest of the code is somewhat difficult to break up coherently. There are only a few important new concepts, however.
if let Bindings
The first concept is if let bindings, which you can read about
here. This control flow construct
allows us to check if the value of an expression matches some pattern, and bind it to
a new variable if so. We can have an else branch on this if let statement as well.
We can check out a brief demo of this pattern on both Options and Results. In the
code below, we have two Options and two Results. The first option is None, while
the second is Some(T) (where T is String in this case). We can pattern match both
of these variables using if let to bind them to a new variable if they match the
pattern (Some(_)) that we are checking for. Notice in the first check, we bind x to
a new variable x, and in the second we bind x to a new variable e. We can do the
same for Result.
fn main() { let x: Option<String> = None; let y: Option<String> = Some("Hello, World!".to_string()); if let Some(x) = x { println!("x is some: {}!", x); } else { println!("x is none"); } if let Some(e) = y { println!("y is some: {}!", e); } else { println!("y is none"); } let w: Result<String, String> = Err("There was something wrong...".into()); let z: Result<String, String> = Ok("Hello, World!".to_string()); if let Ok(z) = z { println!("z was ok: {}!", z); } else { println!("z was not ok"); } if let Err(e) = w { println!("w was err: {}!", e); } else { println!("w was ok"); } }
In the first check in our code, we checked if rest is Some (Option<T> values
in rust are either Some(T) or None). If so, we bind it to a new variable (also
called rest, there is no need to choose a new name, this newly bound variable has a
smaller scope). We use the if let pattern again, to check if we have at least 2
characters at the beginning of rest:
#![allow(unused)] fn main() { if let Some(rest) = rest { if let Some(&[first, second]) = rest.get(0..2) { }
Ranges
The .get() call uses a range (0..2) from 0 to 2, inclusive on the low and
exclusive on the high end of the range:
#![allow(unused)] fn main() { if let Some(&[first, second]) = rest.get(0..2) { }
Ranges are first-class objects in Rust and work in a similar way as in Python (although
with .. instead of :). The String
Slices
section goes into depth on slice syntax.
The rest of the code parses the escape hex codes and takes an appropriate action based
on the values, writing to the output data and incrementing the pointer we are writing
through as needed. Finally, we construct a vector from the pointer, decoded size, and a
capacity (which we just provide the size as) and return it. Note that unlike earlier,
the unsafe code we are running here truly is unsafe. Because we don't calculate our
buffer size correctly, these writes can go out of bounds of the allocated memory,
causing heap corruption.
Test the Fuzz Target
Like any good developers, we will create a few unit tests for our code before we worry about fuzzing or any additional security testing.
We can add our tests directly in lib.rs. The #[cfg(test)] annotation ensures this
code is only compiled when testing (i.e. it will not take up any space in any final
binaries using this code). The #[test] annotation marks each function as a test entry
point, so the Cargo test harness will run each in a separate thread by default.
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; #[test] fn it_decodes_successfully_emoji() { let expected = String::from("👾 Exterminate!").as_bytes().to_vec(); let encoded = "%F0%9F%91%BE%20Exterminate%21".as_bytes(); assert_eq!(expected, decode(encoded)); } #[test] fn it_decodes_misc() { assert_eq!("".as_bytes().to_vec(), decode("".as_bytes())); assert_eq!( "pureascii".as_bytes().to_vec(), decode("pureascii".as_bytes()) ); assert_eq!("\0".as_bytes().to_vec(), decode("\0".as_bytes())); assert_eq!( "this that".as_bytes().to_vec(), decode("this%20that".as_bytes()) ); } // #[test] // fn it_crashes() { // println!("{:?}", decode("aaaaaaaaaaaaaaaa%%%%%%%%%%%%".as_bytes())); // } } }
Note that we have a third test here commented out. Run cargo test in your crate.
$ cargo test
Compiling first-targetv0.1.0 (/workspaces/documentation.security.fuzzing.libafl/first-target)
Finished test [unoptimized + debuginfo] target(s) in 0.33s
Running unittests src/lib.rs (target/debug/deps/first_target-49e422aa7de12c55)
running 2 tests
test tests::it_decodes_misc ... ok
test tests::it_decodes_successfully_emoji ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Analyzing the Bug
Our unit tests pass! Now lets check out what happens if we uncomment the third function.
$ cargo test
Compiling first-targetv0.1.0 (/workspaces/documentation.security.fuzzing.libafl/first-target)
Finished test [unoptimized + debuginfo] target(s) in 0.27s
Running unittests src/lib.rs (target/debug/deps/first_target-49e422aa7de12c55)
running 3 tests
malloc(): corrupted top size
error: test failed, to rerun pass `--lib`
Caused by:
process didn't exit successfully: `/workspaces/documentation.security.fuzzing.libafl/first-target/target/debug/deps/first_target-49e422aa7de12c55` (signal: 6, SIGABRT: process abort signal)
The program crashes with an error in libc malloc. We've corrupted the top chunk
size, so malloc crashes. We can investigate exactly where this error occurs in the
malloc source code by searching the error message, and we find out it happens
here.
What's happening is that we only have one allocation in our program, so the heap looks
like the image below. Recall the heap grows from low to high addresses (left to right
below).

The "top chunk" is a special chunk that contains all the memory that hasn't been
allocated yet, and is also known as the "wilderness". When we write out of bounds of the
memory we allocated for decoded, we overwrite the mchunk_size field of the metadata
of the top chunk. This can lead to an attack known as House of
Force.
This specific attack isn't important for our fuzzing, but it's a good case study of how
dangerous an error as simple as naive size calculation can be. Not to mention, we end up
incorrectly handling trailing % characters!
If you don't see an error on your system, that's ok. It's somewhat dependent on what
libc version is in use (if you are on Linux), and what size of overflow we end up
performing. Even if this function doesn't crash on your system, our fuzzer will be able
to crash it with some input it will come up with. Go ahead and re-comment that
test function.
Summary
In this section, we learned about:
- Choosing a good fuzz target
- Rust
letbindings - Rust ownership, references, slices, mutable and immutable borrowing
- The basics of
unsafeRust including allocation and using raw pointers - Rust loops, iterators, raw pointer arithmetic,
if letbindings, and ranges - Rust tests
- Triaging a simple heap overflow by searching on GitHub
Create The Fuzzer Crate
Navigate back to the directory containing fuzz-target. Then, create a fuzzer crate and
navigate to it, then run it to make sure everything is set up correctly:
$ cargo new --bin first-fuzzer
$ cd first-fuzzer
$ cargo run --bin first-fuzzer
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/first-fuzzer`
Hello, world!
Add the LibAFL Crate as a Dependency
To add LibAFL as a dependency to our crate, we can just run:
$ cargo add libafl@0.11.2
This may take a minute because it will update your crates.io index if this is the
first time you have added a crates.io dependency.
Check that the depedency is added by viewing the Cargo.toml for the crate. It should
have libafl = "0.11.2" under the [dependencies] section.
Let's check to make sure we can build and run with the dependency added.
$ cargo build
$ cargo run --bin first-fuzzer
You should have the same result as above, but you'll see libafl and its
sub-dependencies compile.
Add LibAFL-Targets Crate as a Dependency
We need to utilize data structures from libafl_targets to interpret the coverage
information being gathered by the instrumentation. To do that, we'll depend on the
crate the same way we did in our target.
We can add libafl_targets with the sancov_8bit and observers feature to our crate
by adding this line to our Cargo.toml file under the [dependencies] section:
libafl_targets = { version = "0.11.2", features = [
"sancov_8bit",
"observers",
] }
Add the Target Crate as a Dependency
In order to link in our fuzz target and call it from our fuzzer, we need to add it as a dependency. Run:
$ cargo add --path ../first-target
You should see the following line appear in your Cargo.toml file under
[dependencies]:
first-target = { version = "0.1.0", path = "../first-target" }
Add Additional Dependencies
We'll use another two dependencies in our fuzzer:
clap, for command-line argument parsing. We'll use thederivefeature to make creating our argument parser super easy.mimalloc, to allow our fuzzer to use a separate allocator from our target.
Add them by running:
$ cargo add clap --features=derive
$ cargo add mimalloc
Create a Build Script
cargo supports build scripts (you can read the documentation on them
here). By creating a
build.rs file in our crate directory, cargo will run it before compiling the crate.
build.rs scripts provide a few key features, notably the ability to modify or add
linking information during crate compilation. We need our build script to do two things:
- Compile
first-targetwith the coverage sanitizer enabled - Tell
cargo(and through it,rustc) to link with the coverage sanitized library when compiling the fuzzer binary
Coverage Sanitizer
Before we use it, we need a bit of background on what a coverage sanitizer actually is, as well as what sanitizer interface we will use for this fuzzer.
LLVM and MSVC provide a feature called SanitizerCoverage. Code coverage is a relatively simple concept, and it is explained well by the documentation. Our goal is simply to measure how much of the code we care about is executed as well as which parts of the code we care about are executed for each fuzzing run.
SanitizerCoverage is implemented at the LLVM level of compilation, and has several
optional implementations:
- PC Trace: a function is called on each control flow edge in the program.
- Guards: a function is called on each control flow edge in the program that is only triggered if a guard value is true. Same as PC trace with guards added.
- Counters: a per-edge counter variable is incremented on each traversal of the edge
- PC Table: Adds a table describing whether each block starting at
pcis a function entry block or not
The exact arguments change over time with new LLVM releases, but the LLVM Doxygen describes all of them.
For this fuzzer, we will use the following options for SanitizerCoverage:
-sanitizer-coverage-level=3: Level 3 is all blocks and critical edges.-sanitizer-coverage-inline-8bit-counters: Use counters to track how many times each edge is hit.-sanitizer-coverage-prune-blocks=0: Don't remove coverage info from any blocks.passes=sancov-module: Tells LLVM to run theSanitizerCoveragemodule.
The Build Script
To pass arguments to the compilation of a specific dependency, we can use the
cargo rustc subprogram. This lets us pass arguments to rustc, the Rust compiler, as
well as to LLVM, which rustc uses for final code generation and
additional optimization. We'll use std::process::Command, which is similar to using
subprocess.Popen in Python or system in C, although much more flexible.
We'll walk through the cargo rustc arguments that we'll add in addition to the
SanitizerCoverage flags.
-p first-target-solution: Tellrustcto just build the target with these arguments, rather than pass these arguments to all the code we're compiling.--target-dir target/first-target/: Tellrustcto build in a subdirectory of the defaulttargetdirectory, to avoid conflicting with the currently running build process' lock on thetargetdirectory.link-dead-code: Don't prune any unused code from the compilation result.lto=no: Don't do link-time optimization, because it might remove some code or instrumentation.--emit=dep-info,link: Emit linking and dependency information.opt-level={}: We just pass the opt level we are compiling the fuzzer at to the target as well. This allows us to use--release.
use std::{env::var, process::Command}; fn main() { let status = Command::new("cargo") .arg("rustc") .arg("-p") .arg("first-target") .arg("--target-dir") .arg("target/first-target/") .arg("--") .arg("-C") .arg(format!( "opt-level={}", var("OPT_LEVEL").expect("No OPT_LEVEL variable set") )) .arg("-C") .arg("prefer-dynamic") .arg("-C") .arg("passes=sancov-module") .arg("-C") .arg("llvm-args=-sanitizer-coverage-level=3") .arg("-C") .arg("llvm-args=-sanitizer-coverage-inline-8bit-counters") .arg("-C") .arg("llvm-args=-sanitizer-coverage-prune-blocks=0") .arg("-C") .arg("link-dead-code") .arg("-C") .arg("lto=no") .arg("--emit=dep-info,link") .status() .expect("Failed to spawn Cargo"); assert!(status.success(), "Target build command failed");
We'll also use some specially formatted print statements in our build script to instruct
cargo to link with the library. Note the env! macro, which grabs the value of an
environment variable at compile time (and is a compile error if the variable isn't
present). The CARGO_MANIFEST_DIR environment variable is set automatically by cargo
during build script compilation and execution. You can check the full list of these
environment variables
here. You can
also check out the full list of special print messages
here.
#![allow(unused)] fn main() { println!( "cargo:rustc-link-search={}/target/first-target/debug/", env!("CARGO_MANIFEST_DIR") ); println!("cargo:rustc-link-lib=static=first_target"); } }
Delete The Template main.rs
We're ready to write some code. Delete the template code out of your main.rs file and
add an empty main function like this:
fn main() {}
Set The Global Allocator
Rust allows us to choose any allocator we want as the global allocator that will be used
for all our allocations. We are using the
mimalloc allocator. We can set it as the
global allocator by adding a couple lines to our fuzzer's main.rs above the main
function.
#![allow(unused)] fn main() { use mimalloc::MiMalloc; #[global_allocator] static GLOBAL: MiMalloc = MiMalloc; }
This lets us use a different allocator in our fuzzer than is being called by our target, so when the target malloc state gets corrupted we won't crash the fuzzer.
Import Coverage Observer
We'll discuss the coverage observer in greater detail later, but you can use it from
the libafl_targets dependency like so:
#![allow(unused)] fn main() { use libafl_targets::CountersMultiMapObserver; }
This is necessary so we have the type of the observer available to us.
Declare Functions From Target
Because we are linking with our target statically, we need to declare the functions
we want to call from it as extern. This has the same meaning as in C/C++, and informs
the compiler that we will link with these symbols, but we are not defining them.
Add the following block below the allocator definition.
#![allow(unused)] fn main() { extern "Rust" { fn decode(encoded_input: &[u8]) -> Vec<u8>; fn counters_maps_observer(name: &'static str) -> CountersMultiMapObserver<false>; } }
Add An Argument Parser
We want to be able to easily pass in a path to our input corpus of test cases as well as a directory the fuzzer should put solutions (or crashing inputs) when it finds them.
We can implement argument parsing easily with the clap crate (documentation
here). Clap is super
flexible and powerful, but we'll just add two arguments, the two paths we mentioned
above. Add this to your main.rs above your main function.
#![allow(unused)] fn main() { use clap::Parser; #[derive(Parser)] struct Args { #[arg(short, long)] /// Corpus directory corpus: PathBuf, #[arg(short, long)] /// Solutions directory solutions: PathBuf, } }
Now add the first line of our main function:
fn main() { let args = Args::parse(); }
Derive Macros
Derive macros allow us to add an attribute to a struct
that automatically adds some functionality for us. In this case, deriving Parser
automatically adds the parse static method to the Args struct. Calling it will
automatically parse command line arguments for us (including some default extras, like
-h for help) and give us an initialized Args struct we can use to grab the two paths
we have as arguments. We give extra info to the derive by adding attributes to the
fields of the struct as well, so clap knows we want to have short and long argument
flags for those fields, instead of them being positional arguments.
cargo build
When we run cargo build, we have seen that cargo will:
- Run our build script
- Build (compile) our crate
When we build an executable like our fuzzer with cargo build, cargo will put the
resulting binary in target/debug/<EXECUTABLE_NAME>. Let's go ahead and build our
fuzzer:
$ cargo build
$ ls target/debug/
build deps examples first-fuzzer first-fuzzer.d incremental
We can run our first-fuzzer binary:
$ ./target/debug/first-fuzzer -h
Usage: first-fuzzer --corpus <CORPUS> --solutions <SOLUTIONS>
Options:
-c, --corpus <CORPUS> Corpus directory
-s, --solutions <SOLUTIONS> Solutions directory
-h, --help Print help
If we build in the release profile with cargo build --release, instead of being
located in the debug subdirectory, our binary will be in the release subdirectory.
Generally, you'll use either the debug (default) profile or the release profile, and
you should always use the release profile when running real fuzzing campaigns.
Otherwise, you are leaving performance on the table!
We can build and run just the same with the release profile:
$ cargo build --release
$ ./target/release/first-fuzzer -h
Finished release [optimized] target(s) in 1.33s
Running `target/release/first-fuzzer -h`
Usage: first-fuzzer --corpus <CORPUS> --solutions <SOLUTIONS>
Options:
-c, --corpus <CORPUS> Corpus directory
-s, --solutions <SOLUTIONS> Solutions directory
-h, --help Print help
cargo run
Instead of having to run cargo build and then run your binary, you can use cargo run
as a shortcut. For example, to build and then run in release mode, we can run:
$ cargo run --release -- -h
Finished release [optimized] target(s) in 1.33s
Running `target/release/first-fuzzer -h`
Usage: first-fuzzer --corpus <CORPUS> --solutions <SOLUTIONS>
Options:
-c, --corpus <CORPUS> Corpus directory
-s, --solutions <SOLUTIONS> Solutions directory
-h, --help Print help
This is exactly the same as building then running, it just saves a step. Note the --
after the cargo arguments to separate arguments to cargo from arguments to our
binary.
From here out, we'll use cargo run whenever we want to run our fuzzer.
Add a Harness
The first part of our fuzzer we'll create is our harness. A harness is the function our fuzzer will actually call directly for each test case it tests. We'll use a closure instead of defining another function, because our harness will be very short.
Closures
Closures in rust are similar to lambdas in both Python and C++, and to a lesser extent function pointers in C. They are anonymous functions that optionally capture data from their surrounding scope (or, as the documentation calls it, their environment). The full scope of capabilities of closures is large and complex, so you are encouraged to read the Closures Documentation.
Create A Harness Closure
Before we can write our closure, we'll need to add a few use declarations from
libafl. Add these at the top of your main.rs file:
#![allow(unused)] fn main() { use libafl::prelude::{BytesInput, AsSlice, HasTargetBytes, ExitKind}; }
BytesInput
is a type that describes an input from the fuzzer that is just a sequence of bytes. It's
the standard input type, although it is possible to define custom input types as we'll
see in later exercises.
BytesInput
under the hood is just a
Vec<u8> with some sugar
around it to make it easy to use in the context of a possibly distributed and
multi-threaded fuzzer.
HasTargetBytes
is a trait (which we will dive deep into later, but for now you can think of as
similar to an interface in Java or a concept in C++) that is implemented by
BytesInput
and returns the contents of the
BytesInput
as an OwnedSlice<u8>.
An
OwnedSlice<T>
wraps a slice (in this case a &[u8]) so that it is serializable (we'll discuss
serializability later) and can be sent between threads, processes, and machines over the
network easily. LibAFL has several Owned types used for this purpose:
OwnedRef<T>,
OwnedRefMut<T>,
OwnedPtr<T>,
OwnedMutPtr<T>,
OwnedSlice<T>
and
OwnedMutSlice<T>.
Each wraps the underlying type, whether it is a &T/&mut T, *const T/*mut T, or
&[T]/&mut [T].
AsSlice is another
trait implemented by
OwnedSlice
and allows the
OwnedSlice<u8>
to be converted to &[u8], which we'll then input to our decode function.
With all that knowledge, our harness closure is pretty simple. We take our
BytesInput,
convert it to an
OwnedSlice<u8>,
convert that to a &[u8], and call our target function.
fn main() { let args = Args::parse(); let mut harness = |input: &BytesInput| { let target = input.target_bytes(); let buf = target.as_slice(); println!("Fuzzing with {:?} ({})", buf, buf.len()); unsafe { decode(buf) }; ExitKind::Ok } }
Add Observers and Feedbacks
We've already discussed how we are instrumenting our target to keep track of coverage information, but we need a way to incorporate the information we get from our 8-bit edge hit counters as feedback to our fuzzer.
LibAFL has two concepts that allow us to do this:
Observers
An Observer in LibAFL implements the
Observer trait. An
Observer is very
generic and does essentially what it sounds like: observes some state.
Observers
optionally implement methods that are called on events that occur each fuzzing iteration
like pre_exec, post_exec, and so forth.
The most familiar Observer
type is the HitcountsMapObserver that observes a region of memory (a bitmap) whose entries are
incremented each time an edge or block is hit during a target execution. This is the
model AFL++ uses by default.
Observers can
also observe other observes, that is, they can be nested. For example, a HitcountsMapObserver observes a
MapObserver
and adds post-processing of hitcounts instead of the raw map data.
We can use one of the many provided implementations, or we can define our own, like with everything in LibAFL.
Feedbacks
A Feedback is a
trait implemented by an object that takes as input the state of an
Observer and
determines, after each fuzzing iteration, whether the state of the observer is
interesting. This interestingness determination is entirely up to the implementer,
although many common cases are implemented by default.
For example, the
AflMapFeedback
implements the interestingness determination used by AFL and AFL++ given the state of a
HitcountsMapObserver.
The interestingness determination from each feedback is used to determine whether a
testcase should be kept, and further mutated, or discarded. The
AflMapFeedback
keeps testcases that exercise any new control flow, whether that is exploring a
previously unexplored edge in the CFG or exploring an explored edge a previously un-seen
number of times (for example, an additional loop iteration).
Add Our Observers and Feedbacks
We will use aCountersMapsObserver wrapped by a
HitcountsIterableMapObserver
to observe the state of our 8-bit instrumentation counters. The
CountersMapsObserver observes the state of the counters directly, and resets the
state of the counters each iteration. The
HitcountsIterableMapObserver will wrap it and allow us to use it with the
AFL-style feedback.
We'll also us the aforementioned
AflMapFeedback
to determine whether inputs are interesting based on the observed hit counter states.
Finally, we'll use a special feedback, the
CrashFeedback
which returns interesting if the harness crashed. We won't use this feedback to inform
our corpus, we'll use it as an Objective which means if this feedback returns
interesting, we will save the input that caused it.
First, we'll add a few use declarations for the types we will be using. Add these
at the top of your file.
#![allow(unused)] fn main() { use libafl::prelude::{AflMapFeedback, CrashFeedback, HitcountsIterableMapObserver}; }
Now we'll add our observers and feedbacks to our main function:
fn main() { let args = Args::parse(); let mut harness = |input: &BytesInput| { let target = input.target_bytes(); let buf = target.as_slice(); println!("Fuzzing with {:?} ({})", buf, buf.len()); unsafe { decode(buf) }; ExitKind::Ok } let counters_observer = HitcountsIterableMapObserver::new(unsafe { counters_maps_observer("counters-maps") }); let counters_feedback = AflMapFeedback::new(&counters_observer); let mut objective = CrashFeedback::new(); }
Notice that we print out our buffer and its length, just so we can see what is happening when we run it later.
Add Random Provider, Corpus, Solution Corpus, and State
This may sound like a lot of components, but for simple and even somewhat advanced cases, we can use the provided default implementations for all of these components.
Random Provider
Random providers provide random data, generally optimized for speed because fuzzing does not require cryptographically secure randomness.
We will use the default StdRand:
Add the use declaration for it:
#![allow(unused)] fn main() { use libafl::prelude::{StdRand, current_nanos}; }
And create the random source in your main function:
#![allow(unused)] fn main() { let rand = StdRand::with_seed(current_nanos()); }
Corpus
We will keep our working corpus in memory for efficiency, so we'll want to create
a new InMemoryCorpus.
Add the use declaration for it:
#![allow(unused)] fn main() { use libafl::prelude::InMemoryCorpus; }
And create a new corpus in your main function:
#![allow(unused)] fn main() { let corpus = InMemoryCorpus::new(); }
Solution Corpus
Unlike our working corpus, we want to keep any solutions we find, so we'll store them on
disk. We can use an
OnDiskCorpus
to store solutions (crashes) that we discover. We'll add the use declaration:
#![allow(unused)] fn main() { use libafl::prelude::OnDiskCorpus; }
We'll create our corpus at the path we specify in our program arguments, and panic with an appropriate error message if the operation fails.
#![allow(unused)] fn main() { let solutions = OnDiskCorpus::new(&args.solutions).unwrap_or_else(|e| { panic!( "Unable to create OnDiskCorpus at {}: {}", args.solutions.display(), e ) }); }
State
Now that we have created all the parts of the fuzzer that make up the
State, we can create
one. The State trait
only has one default implementation. The state tracks all the information in the fuzzing
campaign including metadata like executions, the corpus, and more.
Add the use declarations we need:
#![allow(unused)] fn main() { use libafl::state::StdState; }
And we'll create a
StdState with
our corpus, random provider, feedback, and objective:
#![allow(unused)] fn main() { let mut state = StdState::new( rand, corpus, solutions, &mut counters_feedback, &mut objective, ) .expect("Failed to create state"); }
Add Monitor, Event Manager, Scheduler, and Fuzzer
Similar to before, these components are relatively plug-and-play. They offer customization but we don't need to use it for such a simple fuzzer.
Monitor
A Monitor tracks
the state of the fuzzing campaign and displays information and statistics to the user.
There are many options for Monitors
from full-featured TUIs to basic loggers. We will just print out every message we see
to the terminal, the simplest possible logger.
Add the use declaration:
#![allow(unused)] fn main() { use libafl::prelude::SimpleMonitor; }
And create the monitor, wrapping a closure that prints its argument:
#![allow(unused)] fn main() { let mon = SimpleMonitor::new(|s| println!("{}", s)); }
Event Manager
The EventManager
handles events that occur during fuzzing and takes action as needed. For a single-core
local fuzzer, this handling is simple, it primarily passes events to the Monitor to
be displayed, but there are complex event managers that handle synchronization across
machines, restart the fuzzer on specific events, and more.
We'll use the SimpleEventmanager. Add the use declaration:
#![allow(unused)] fn main() { use libafl::prelude::SimpleEventManager; }
And create the manager:
#![allow(unused)] fn main() { let mut mgr = SimpleEventManager::new(mon); }
Scheduler
Scheduling test cases ranges from very easy (test all cases in order as they are generated, or randomly) to very complex (minimization, environmental friendliness, coverage accounting). LibAFL of course also allows you to define new corpus scheduling methods as well, but for our purposes a simple queue is more than sufficient.
Add the use declaration for the QueueScheduler:
#![allow(unused)] fn main() { use libafl::prelude::QueueScheduler; }
And create one:
#![allow(unused)] fn main() { let scheduler = QueueScheduler::new(); }
Fuzzer
Finally, we'll create the Fuzzer.
The fuzzer is the frontend to execution and kicks everything off.
Add the use declaration for it (and the Fuzzer trait):
#![allow(unused)] fn main() { use libafl::{StdFuzzer, Fuzzer}; }
And create the fuzzer:
#![allow(unused)] fn main() { let mut fuzzer = StdFuzzer::new(scheduler, counters_feedback, objective); }
Add Executor, Mutator, and Stages
Executor
The final piece of the test case execution puzzle is the Executor. Executors provide different ways to actually run the harness, whether
by forking then executing the harness, running it by directly calling the function,
executing a command on the system, and more. We will use the simplest one, the
InProcessExecutor
which will just call our harness over and over with new testcases.
Add the use declaration for it, and the tuple_list macro which we use to create
a tuple of observers to pass in. In our case, we only have one, so we create a tuple
of one value.
#![allow(unused)] fn main() { use libafl::prelude::{InProcessExecutor, tuple_list}; }
Then create the executor:
#![allow(unused)] fn main() { let mut executor = InProcessExecutor::new( &mut harness, tuple_list!(counters_observer), &mut fuzzer, &mut state, &mut mgr, ) .expect("Failed to create the Executor"); }
Mutator
The Mutator is
similar to the scheduler in terms of how complex it can become if you want it to. In our
case, we'll again opt for the simplest option, the
StdScheduledMutator.
Add a use for the mutator and the well known havoc set of mutation strategies which
includes common operations like bit and byte flips, pastes, add and subtract, and more,
which we'll use in our mutator.
#![allow(unused)] fn main() { use libafl::prelude::{StdScheduledMutator, havoc_mutations}; }
And create the mutator.
#![allow(unused)] fn main() { let mutator = StdScheduledMutator::new(havoc_mutations()); }
Stages
The Stages of a
fuzzing campaign are the set of steps the fuzzer moves through for each cycle of the
fuzzer. These stages can include mutation (and almost always do), but can also include
various other steps like symbolic execution, corpus minimization, synchronization
between fuzzers, and more.
For the final time, we will opt for the simplest option and use only a single mutational stage with our just-created havoc mutator.
Add the declaration:
#![allow(unused)] fn main() { use std::stages::StdMutationalStage; }
And add the mutational stage. Notice that once again, we have a tuple_list of one
item. This is where we would put more stages, if we had them.
#![allow(unused)] fn main() { let mut stages = tuple_list!(StdMutationalStage::new(mutator)); }
Load the Input Corpus
Before we start fuzzing, we need to load our input corpus. We can load as many corpus entries as we want, and we will load them from our corpus directory argument.
Each initial input will be executed to make sure there is some interesting feedback.
This is a good litmus test to ensure your fuzzer works as intended -- if the fuzzer fails when loading inputs, there is likely something wrong with your observer(s) or feedback(s).
#![allow(unused)] fn main() { state .load_initial_inputs(&mut fuzzer, &mut executor, &mut mgr, &[args.corpus]) .expect("Failed to generate the initial corpus"); }
Start The Fuzz Loop
The very final step, we need to actually start our fuzzer! This will start our fuzzer and it will run until it gets an exit condition. For this simple fuzzer, because we are running our harness in process, we will exit when the target crashes for the first time. Typically, we would continue to fuzz.
#![allow(unused)] fn main() { fuzzer .fuzz_loop(&mut stages, &mut executor, &mut state, &mut mgr) .expect("Error in the fuzzing loop"); }
Run The Fuzzer
Finally, we are done implementing our target and fuzzer. Let's run it!
Add A Corpus Entry
We only really need a single corpus entry for this target, as it's quite easy. We'll create the corpus directory and add one file to it:
$ mkdir corpus
$ echo 'a' > corpus/1
Launch the Fuzzer
We can now launch the fuzzer by running:
$ cargo run --release -- -c corpus -s solutions
The fuzzer should run, then exit somewhat quickly (again, this is a very easy target).
You'll see some output like:
Fuzzing with [37, 37, 37, 37, 37, 112, 37, 127, 127, 127, 127, 127, 112, 63, 66, 63, 63, 63, 63, 63, 66, 46, 63, 63, 63, 37, 37, 37, 92, 148, 148, 148, 148, 37, 37, 92, 157, 157, 157, 157, 157, 157, 99, 157, 157, 157, 92, 92, 31, 37, 37, 38, 37, 37, 37, 37, 37, 37, 37, 120, 120, 37, 37, 37, 5, 37] (66)
Fuzzing with [148, 148, 148, 148, 148, 148, 148, 148, 3, 37, 37, 58, 176, 176, 176, 37, 37, 176, 176, 175, 37, 37, 37, 37, 37, 37, 142, 142, 176, 176, 176, 37, 37, 37, 37, 37, 37, 37, 36, 37, 37, 92, 37, 37, 37] (45)
Fuzzing with [0, 42] (2)
Fuzzing with [137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 27, 37, 37, 37, 37, 37, 37, 36, 219, 92, 4, 0, 37, 37, 39, 26, 37, 162, 176, 176, 109, 153, 153, 92, 92, 93, 65, 109, 153, 134, 153, 153, 0, 0, 0, 0, 153, 37, 37, 92, 92, 92, 92, 92, 153, 134, 153, 153, 0, 0, 0, 0, 153, 37, 38, 93, 0, 0, 0, 0, 92, 94, 92, 92, 153, 153] (79)
Fuzzing with [37, 37, 37, 37, 37, 37, 37, 37, 37, 176, 176, 176, 37, 37, 37, 37, 37, 37, 37, 36, 37, 92, 92, 37, 37, 37, 37, 37, 37, 176, 176, 176, 37, 37, 37, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 37, 37, 37, 92, 0, 0, 16, 0, 92, 92, 92, 92, 92, 92, 92, 92, 37, 37, 37, 38, 37, 37, 37, 37, 37, 37, 37, 37, 37] (76)
Fuzzing with [7, 7, 100, 0, 0, 0, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 6, 229, 7, 7, 100, 101, 100, 100, 100, 100, 155, 100] (28)
Fuzzing with [1, 143, 37, 1, 124, 124, 143, 143, 143, 143] (10)
Fuzzing with [37, 37, 37, 37, 37, 37, 37, 37, 92, 148, 37, 37, 37, 92, 148, 148, 148, 148, 148, 148, 148, 148, 148, 3, 37, 37, 37, 176, 176, 176, 37, 37, 176, 176, 176, 37, 37, 37, 37, 37, 37, 176, 176, 176, 37, 37, 37, 37, 37, 37, 37, 36, 37, 92, 92, 37, 37, 37, 37, 37, 37, 176, 176, 176, 37, 37, 37, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 37, 37, 37, 92, 0, 0, 1, 0, 92, 92, 92, 92, 92, 92, 92, 92, 37, 37, 37, 38, 37, 37, 37, 0, 127, 37, 37, 37, 37] (108)
Fuzzing with [252, 241, 241, 0, 7, 101, 252, 11, 119, 0, 100, 101, 252, 11, 119, 153, 227, 7, 7, 7, 7, 7, 7, 23, 102, 69, 112, 72, 200, 102, 37, 37, 37, 37, 37, 37, 37, 37, 92, 148, 148, 148, 148, 148, 148, 148, 148, 148, 3, 38, 37, 37, 176, 176, 176, 37, 37, 176, 176, 176, 37, 37, 37, 37, 38, 37, 176, 176, 176, 37, 37, 37, 37, 37, 37, 37, 36, 37, 92, 92, 37, 37, 37, 37, 37, 37, 176, 176, 176, 37, 37, 37, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 92, 37, 37, 37, 90, 0, 0, 1, 0, 37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 92, 92, 92, 92, 37, 37, 38, 37, 176, 176, 176, 0, 127, 37, 37, 37, 37, 37, 36, 37, 92, 92, 92, 92, 37, 37, 37, 38, 37, 37, 37, 37, 37, 37, 37, 73, 73] (160)
[Objective #0] run time: 0h-0m-0s, clients: 1, corpus: 43, objectives: 1, executions: 2179, exec/sec: 0.000
This means we have reached an objective! Notice that this fuzzer runs very fast, not even 1 second for our 2179 executions. Speed is a major advantage of LibAFL over AFL++ and other fuzzers, because reaching this speed on a single core in AFL++ is non-trivial and requires work, whereas with LibAFL we can hit this kind of speed with the simplest possible fuzzer!
Triage The Crash
Run the fuzzer a few times and confirm you see an objective each time. We can then view
the crashes in the solutions directory:
$ ls solutions
26c0aa3cb05a20f7 6b47dcc6e8baf69e 6f40a2bea93ee0a3 71fd31f6e02fb1d5 a3ee050a83870a18 e54c970569a44481 e552cbba2b3e2764
We'll create a test case for all these crashes. Create a testcases directory in your
first-target crate, and copy all the inputs into it:
$ cd /path/to/first-target
$ mkdir testcases
$ cp ../first-fuzzer/solutions/* ./testcases
Then, add a test case to mod tests in your lib.rs:
#![allow(unused)] fn main() { #[test] fn it_crashed_by_fuzzer() { let test = include_bytes!("../testcases/26c0aa3cb05a20f7"); decode(test); let test = include_bytes!("../testcases/6b47dcc6e8baf69e"); decode(test); let test = include_bytes!("../testcases/6f40a2bea93ee0a3"); decode(test); let test = include_bytes!("../testcases/71fd31f6e02fb1d5"); decode(test); let test = include_bytes!("../testcases/a3ee050a83870a18"); decode(test); let test = include_bytes!("../testcases/e54c970569a44481"); decode(test); let test = include_bytes!("../testcases/e552cbba2b3e2764"); decode(test); } }
Running cargo test should crash with these inputs (you can separate them into individual
test functions to narrow down which inputs are problematic), and as a developer you could
then debug your program to find the root cause using these crashing inputs.
Summary
You can view the completed source for the fuzzer here.
In this exercise, we learned:
- About creating rust library and binary crates
- How to add dependencies
- What LibAFL_Targets does
- How to choose and create a good fuzz target
- About Rust memory and ownership semantics
- How to unsafely allocate memory
- How to implement a simple decoder
- How to unit test a rust function
- How to instrument a library with SanitizerCoverage
- How to link a fuzzer with a static library
- How to set a new global allocator
- How to create a fuzzer using LibAFL including all its components
- Observers
- Feedbacks
- Fuzzers
- Monitors
- Mutators
- Schedulers
- Stages
- Executors
- ...
- How to parse command line arguments
- How to find crashing inputs using a fuzzer and fix the bugs that cause them
Docker Dev Container
Windows Host
Linux Host
Virtual Machines
Many fuzzing targets can run and be fuzzed entirely in user-space, and many fuzzers require no special kernel modifications or particular operating systems to run them. When this is not the case, it is usually most convenient to use a Virtual Machine, for example when learning to fuzz Kernel Modules/Drivers (on both Windows and Linux), or when particular resources are needed. We provide guides for assembling these development or fuzzing environments that are used throughout this book.
Windows Kernel Development VM
We'll set up Windows for fuzzing and development using VirtualBox.
- Install VirtualBox
- Download Windows
- Create a VM
- Install Windows
- Set Up SSH
- Enable SSH Port Forwarding in VirtualBox
- Change Default Shell to PowerShell
- Installing the EWDK
- Installing Development Tools
Install VirtualBox
Install VirtualBox from virtualbox.org. VirtualBox supports Windows, Linux, and macOS.
Download Windows
Download an ISO for 64-bit Windows 10 from the Microsoft Evaluation Center.
Create a VM
Run VirtualBox. You will be greeted with this window:
Click "New" to create a new Virtual Machine.
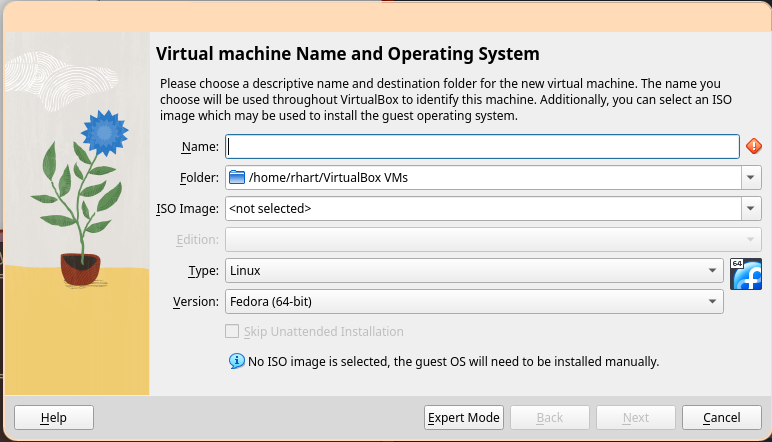
Enter a name, select the ISO image we downloaded, and be sure to check "Skip unattended installation". Then, click "Next".
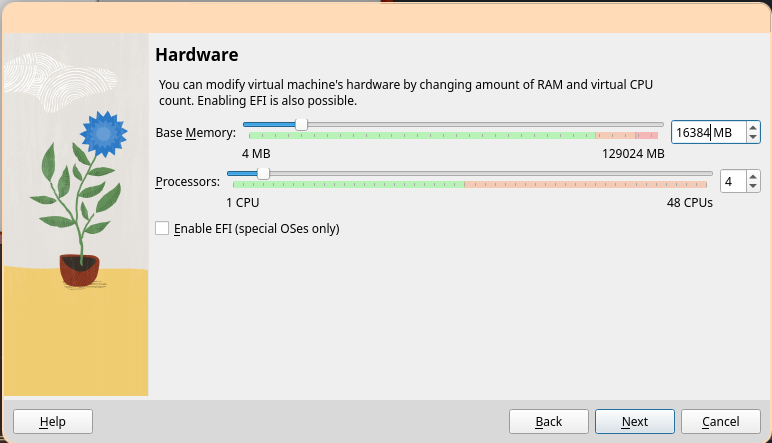
At least 4GB of RAM and 1 CPU is recommended, but add more if you have resources available. Then, click "Next".
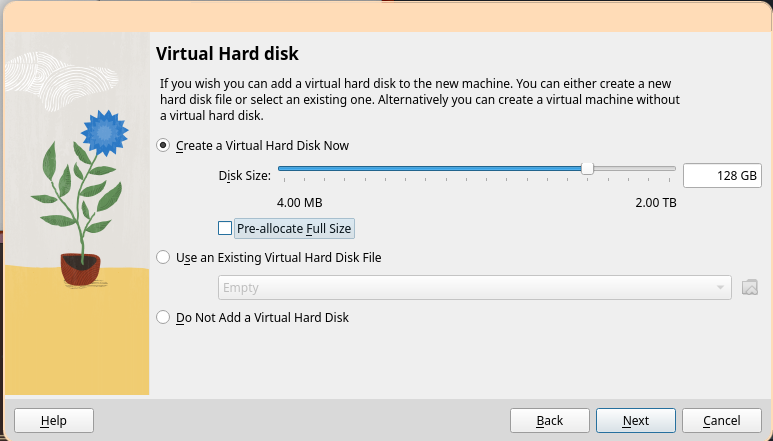
At least 64GB of disk space is recommended to ensure enough space for all required development tools, including Visual Studio and the Windows Driver Kit.
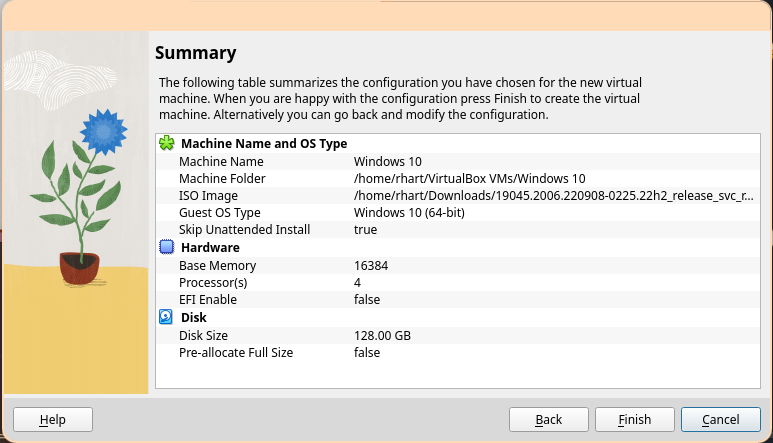
Ensure the settings look correct, then select "Finish".
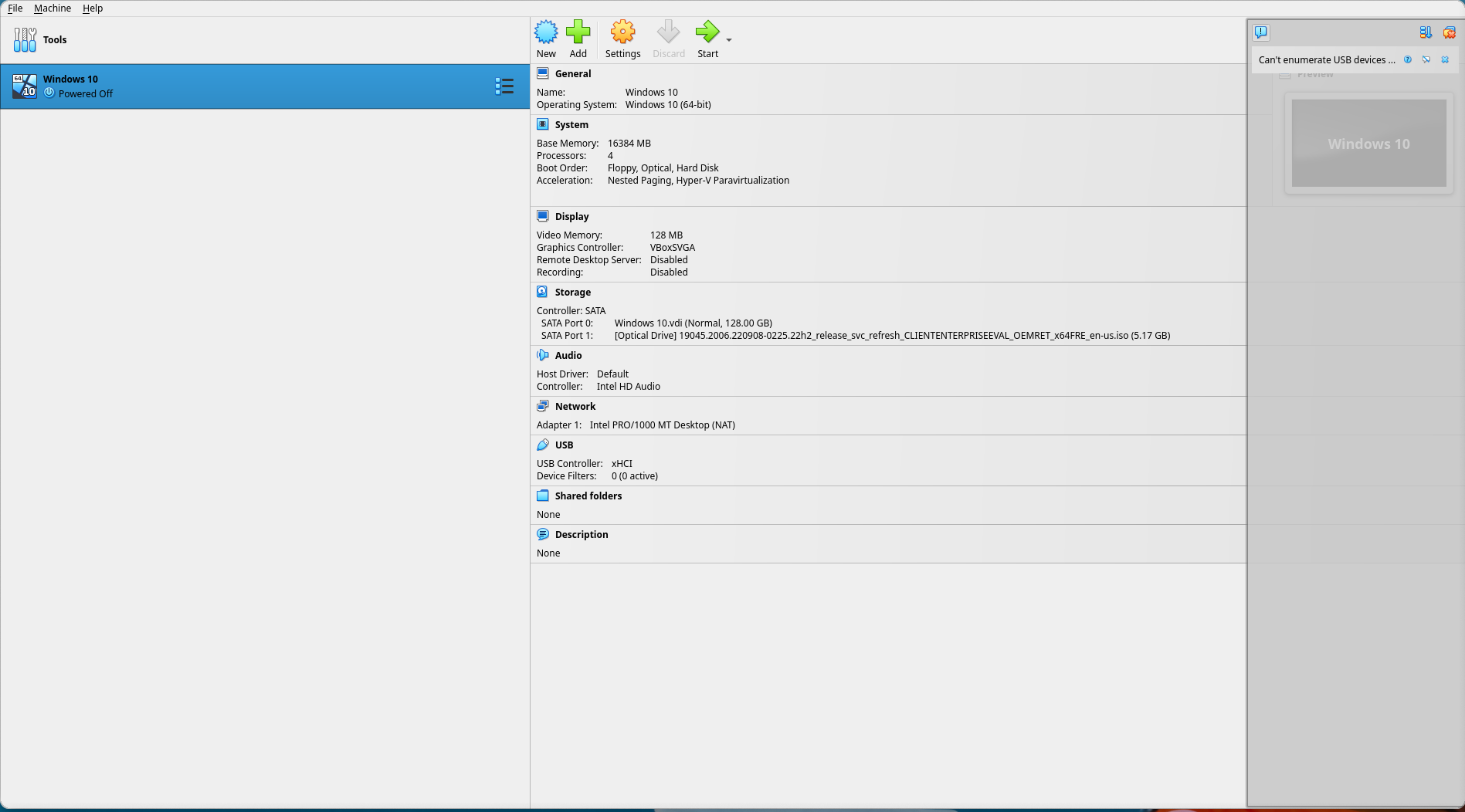
Start the VM by selecting "Start" with the newly created VM selected in the left-hand menu.
Install Windows
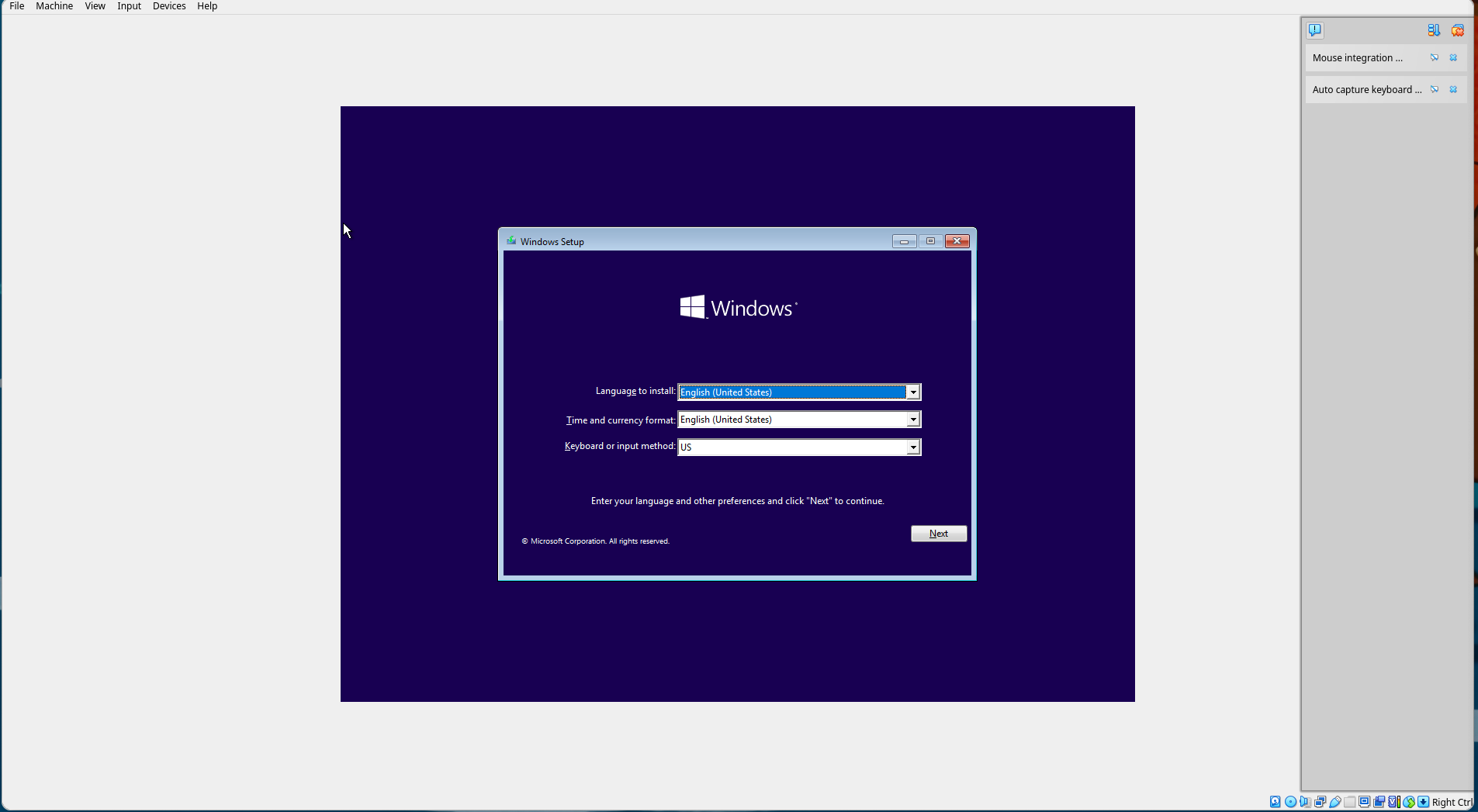
Change the language options if desired, but note the tutorial will assume English.
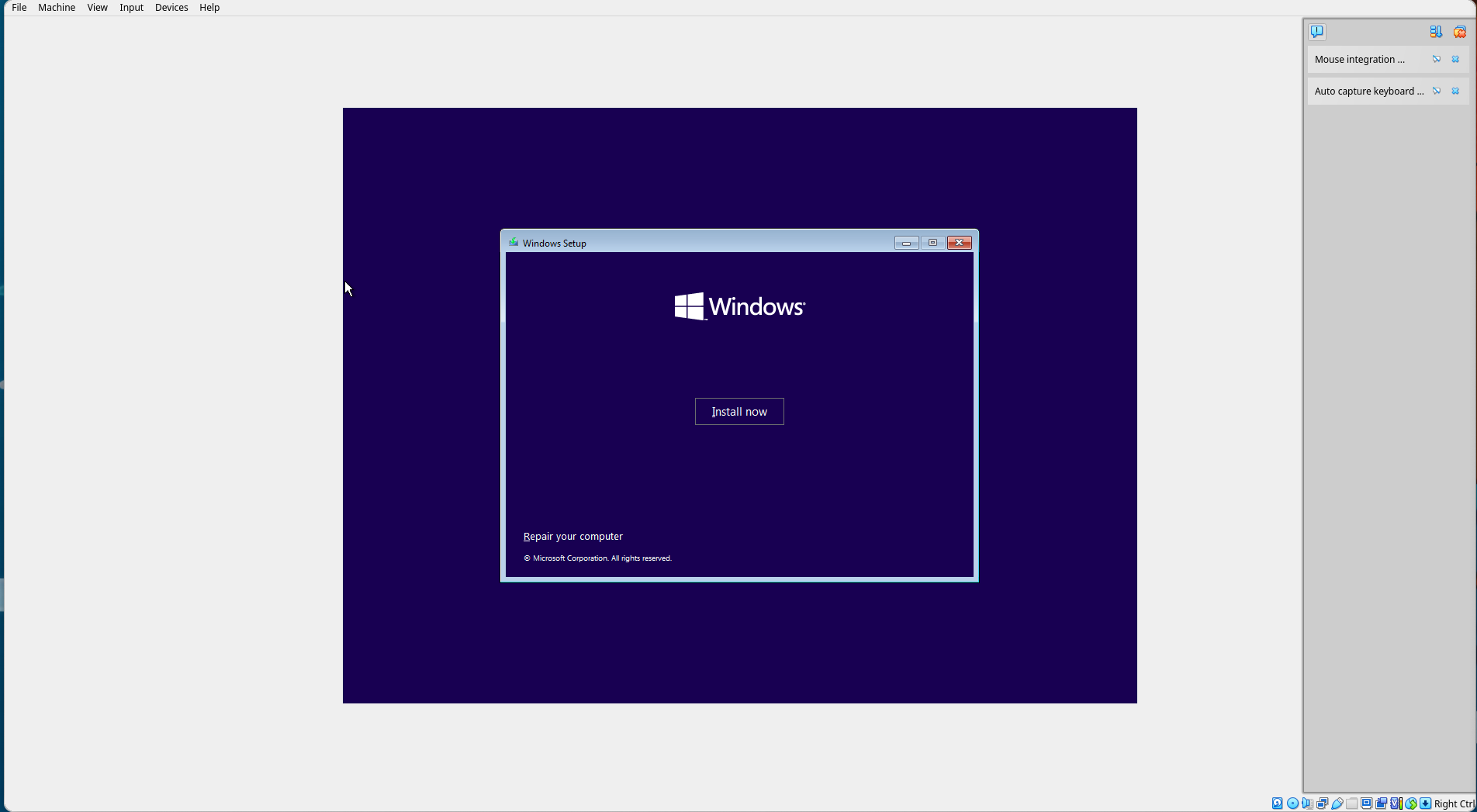
Select "Install Now".
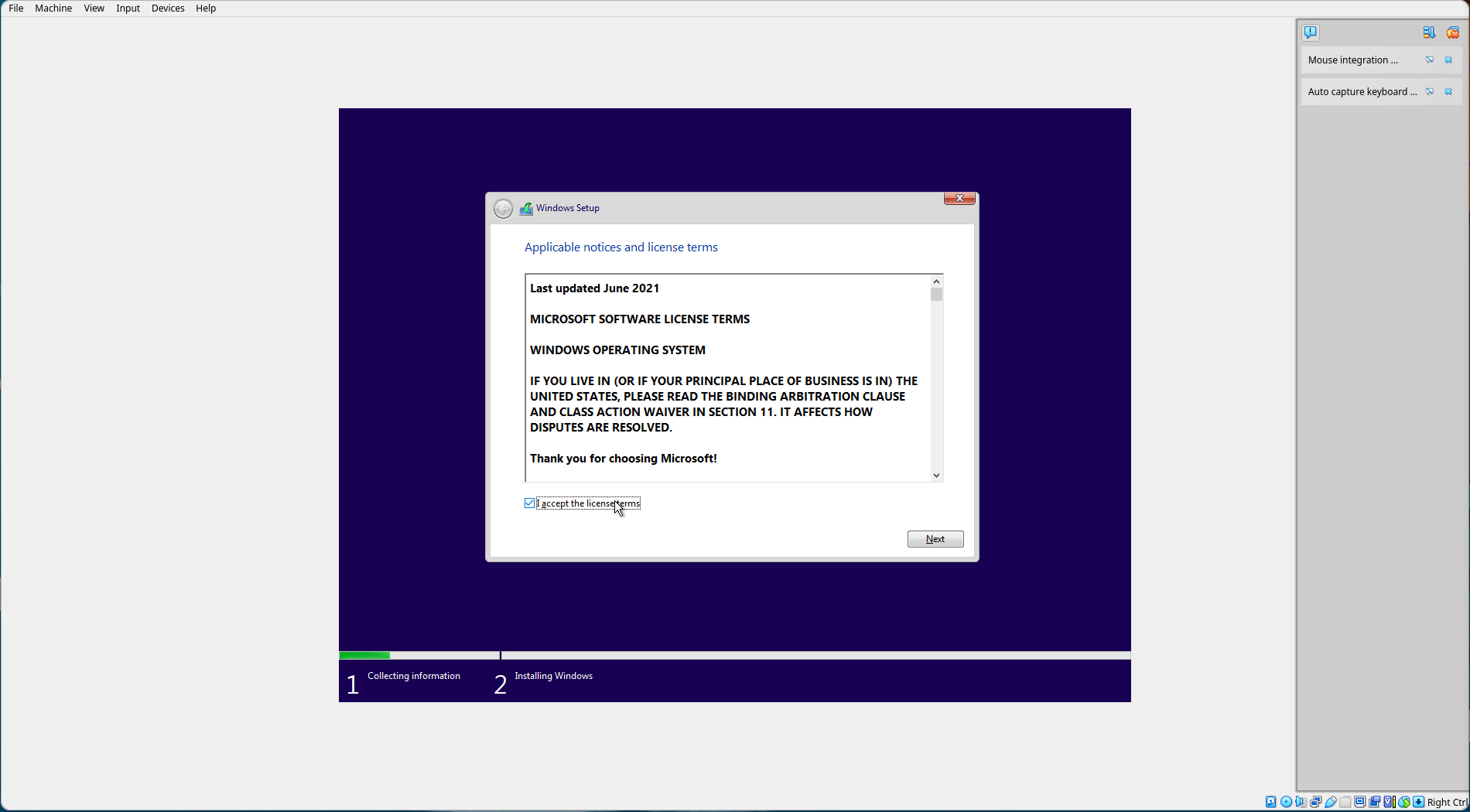
Accept the license terms and select "Next".
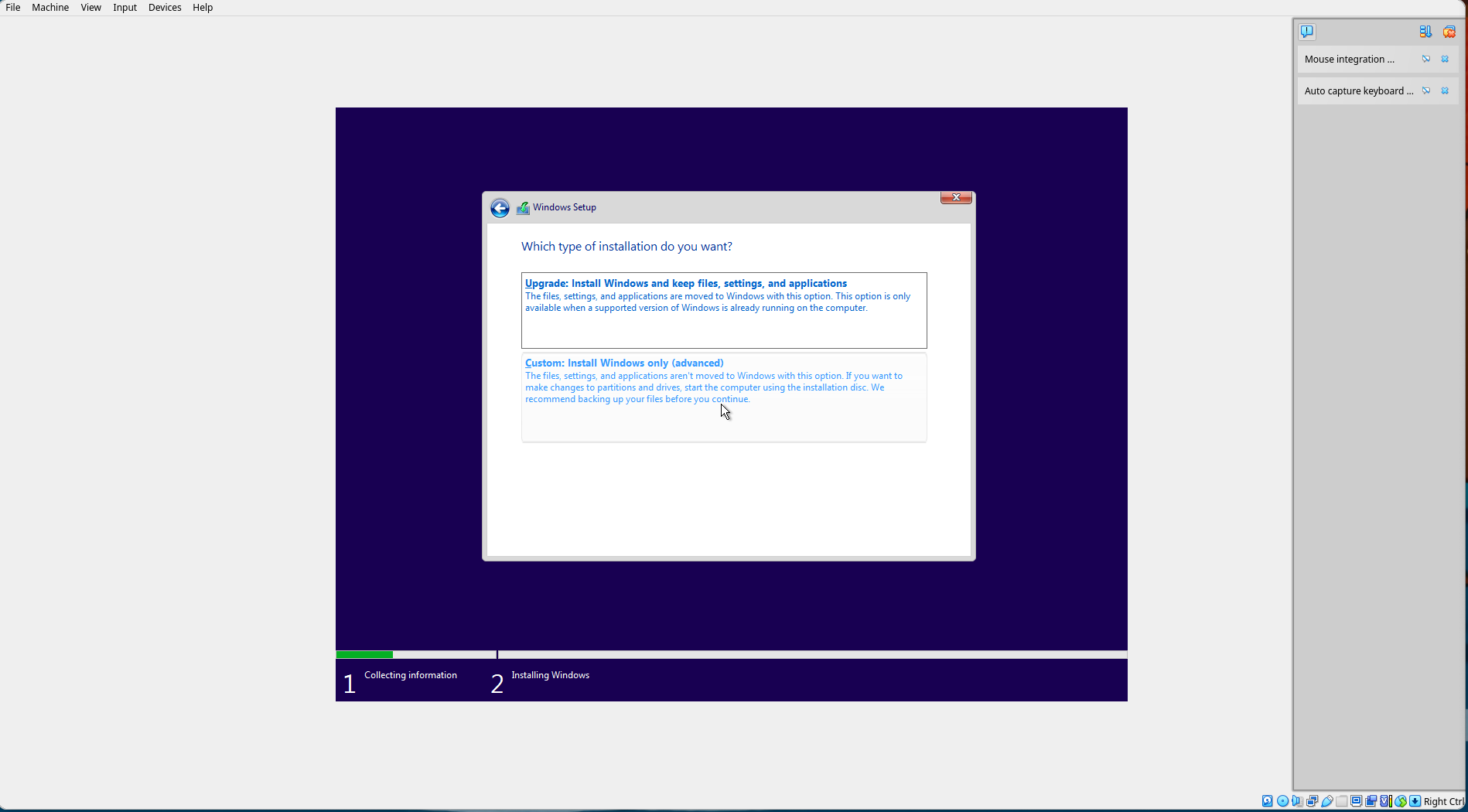
Select "Custom: Install Windows only (advanced)".
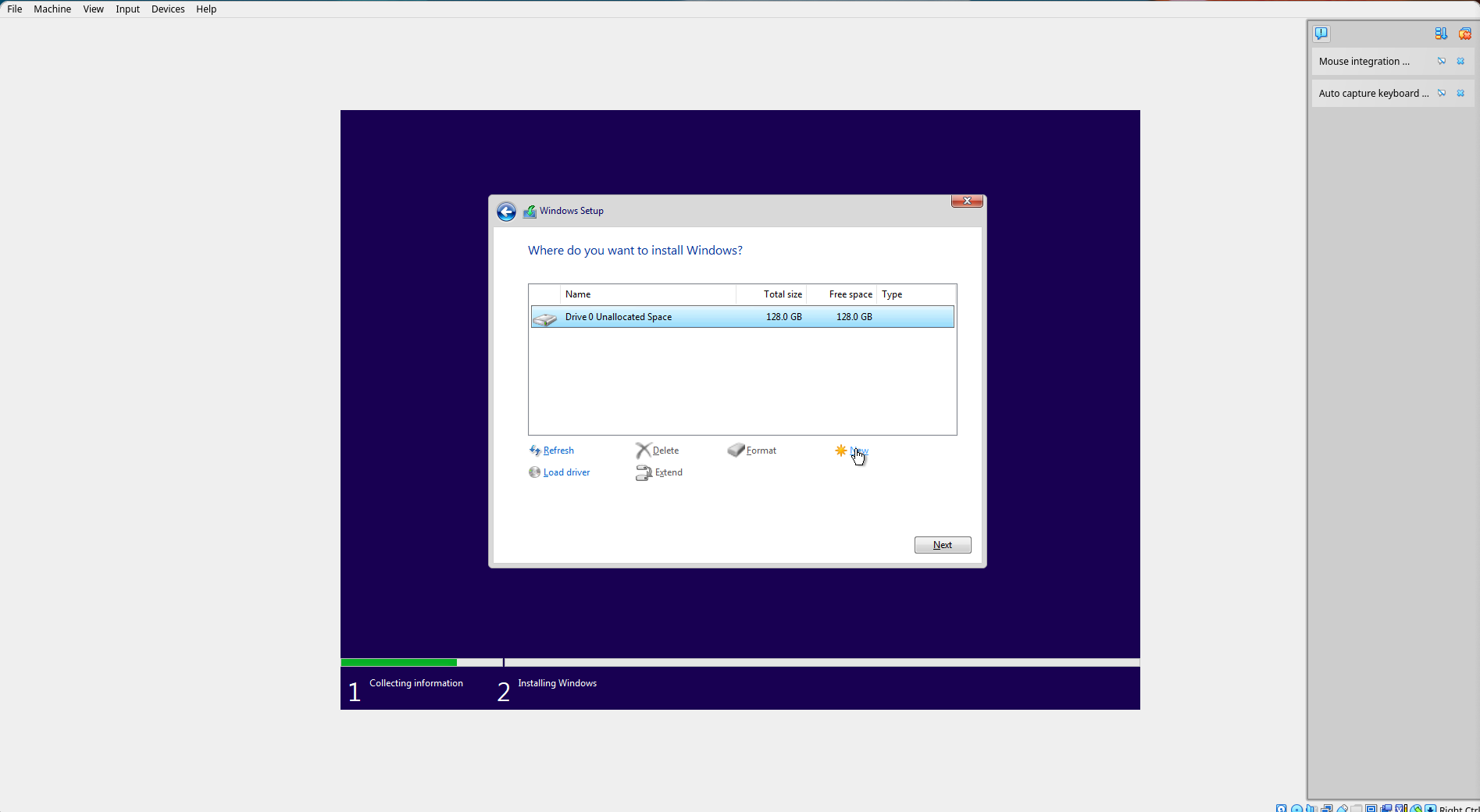
Select "New".
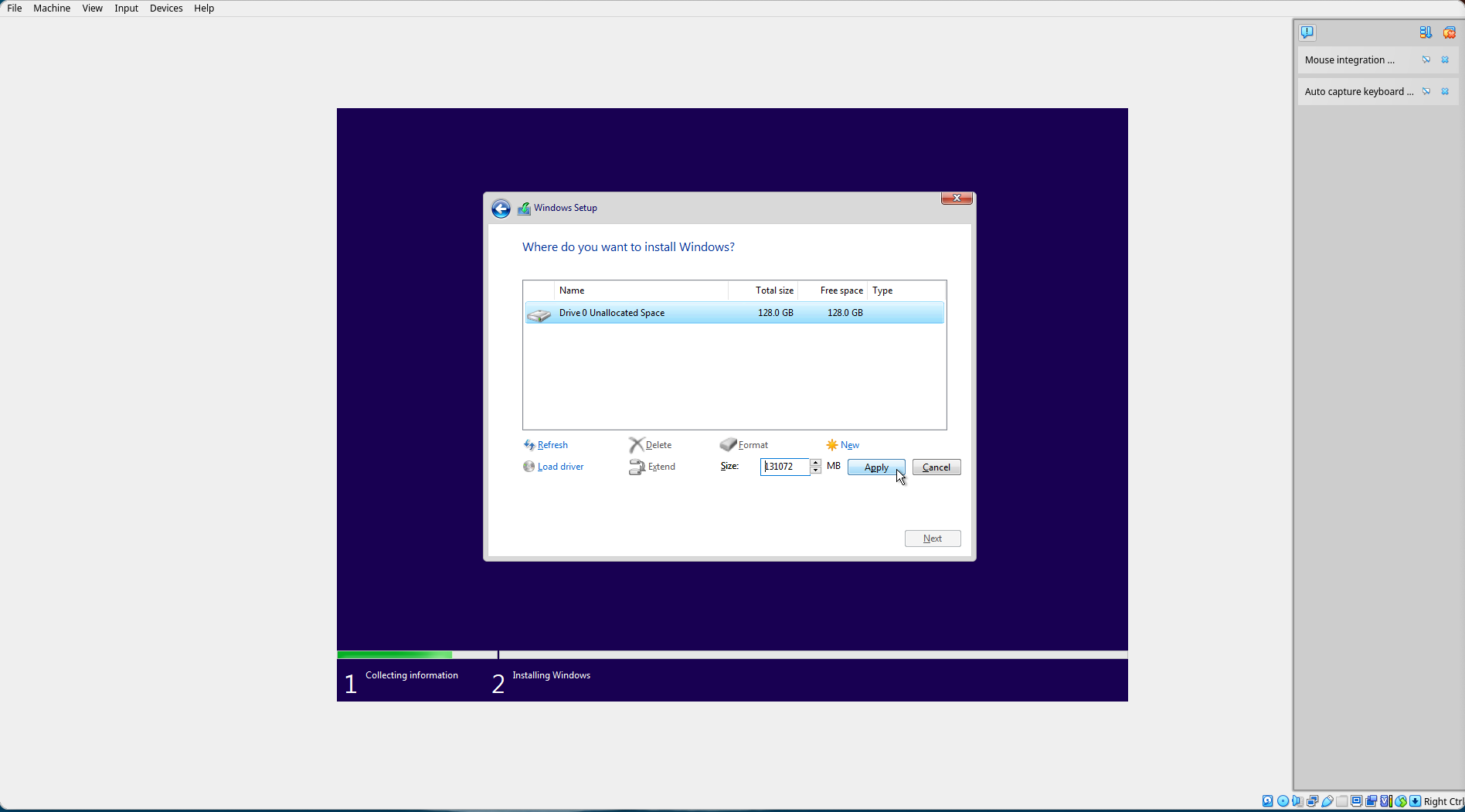
Select "Apply". The default size is the full size of the virtual drive.
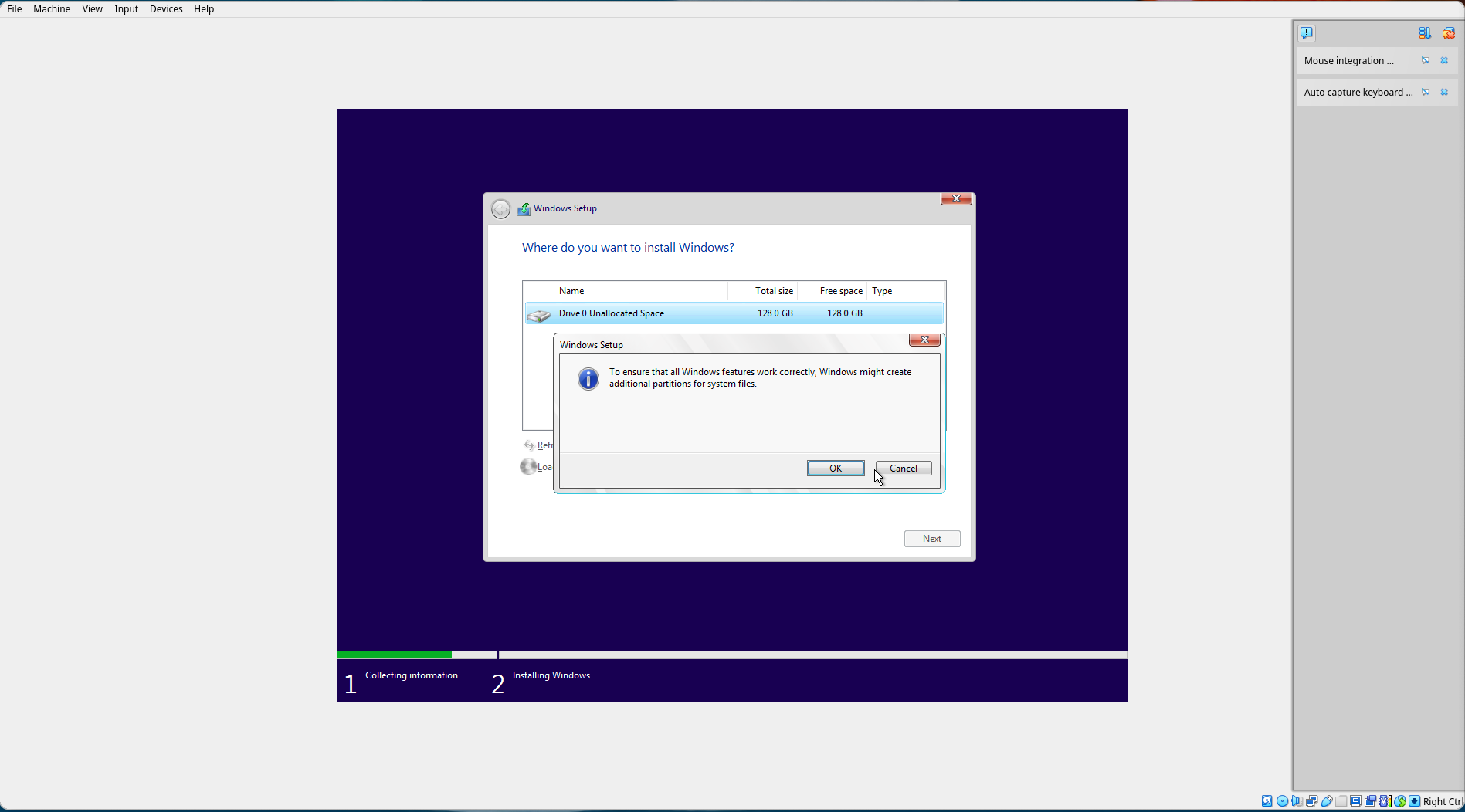
Select "OK".
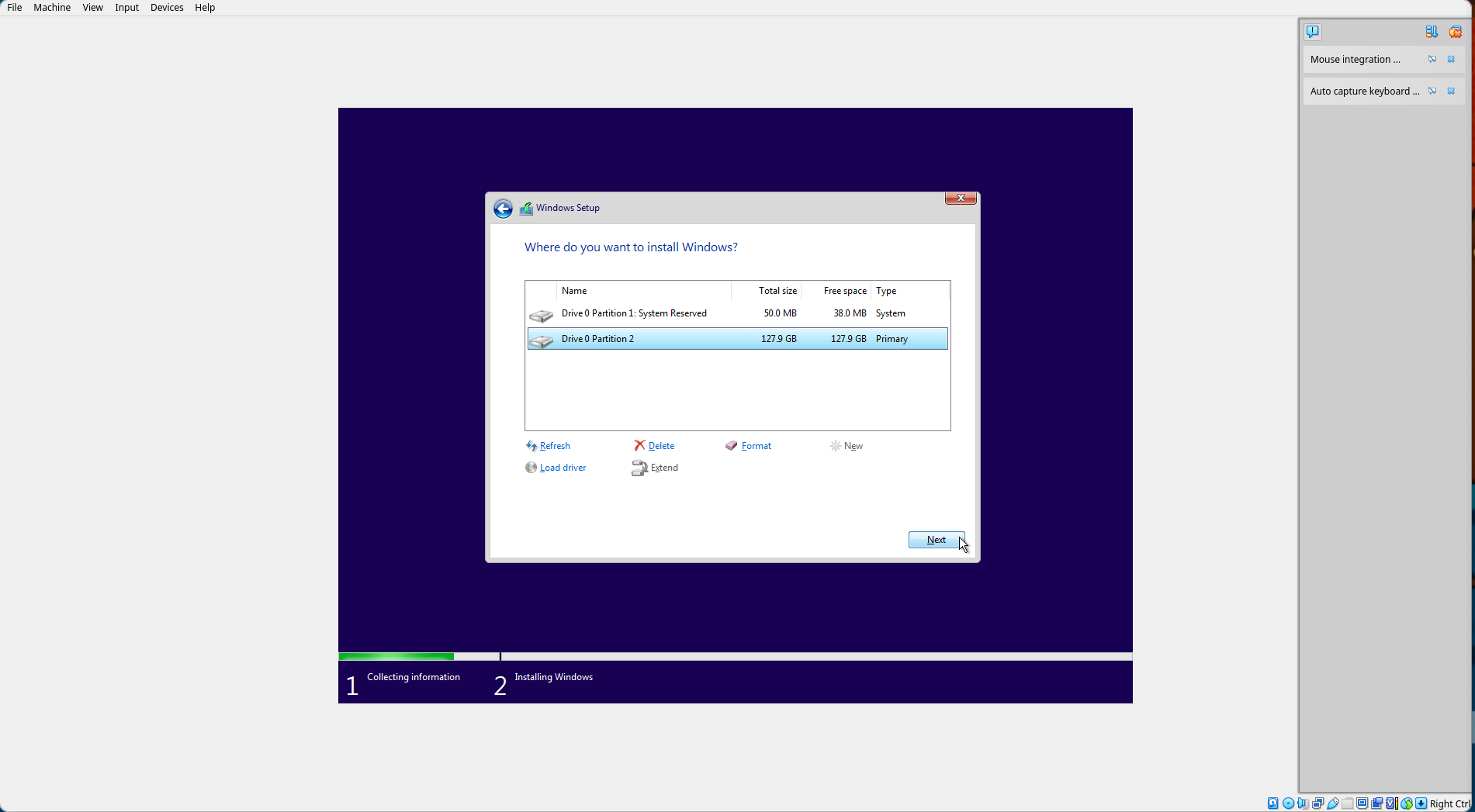
Select "Next".
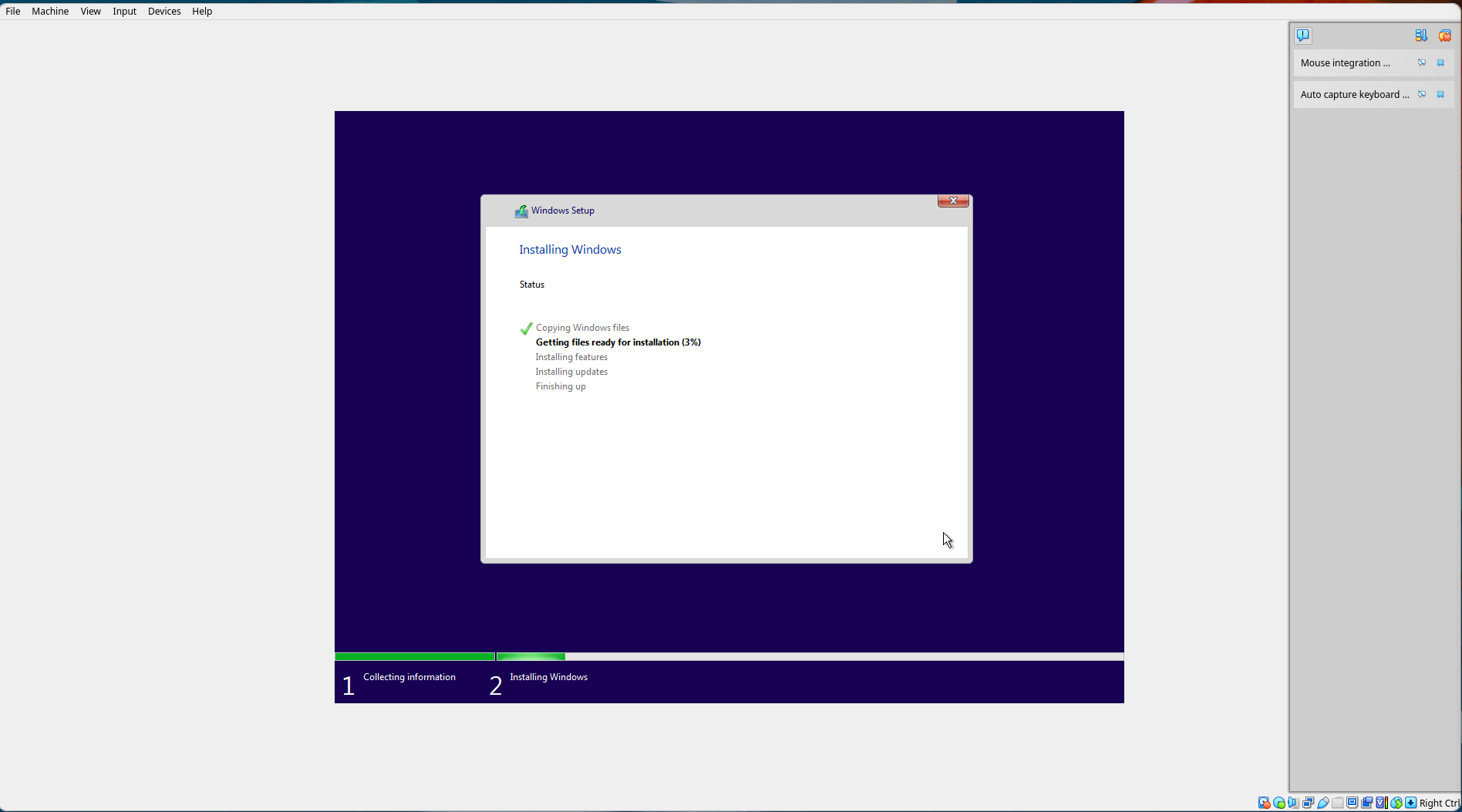
Wait for the installation process to complete. The machine will reboot a couple times. If prompted to press a key to boot from CD or DVD, do not press anything, because we do not want to do that.
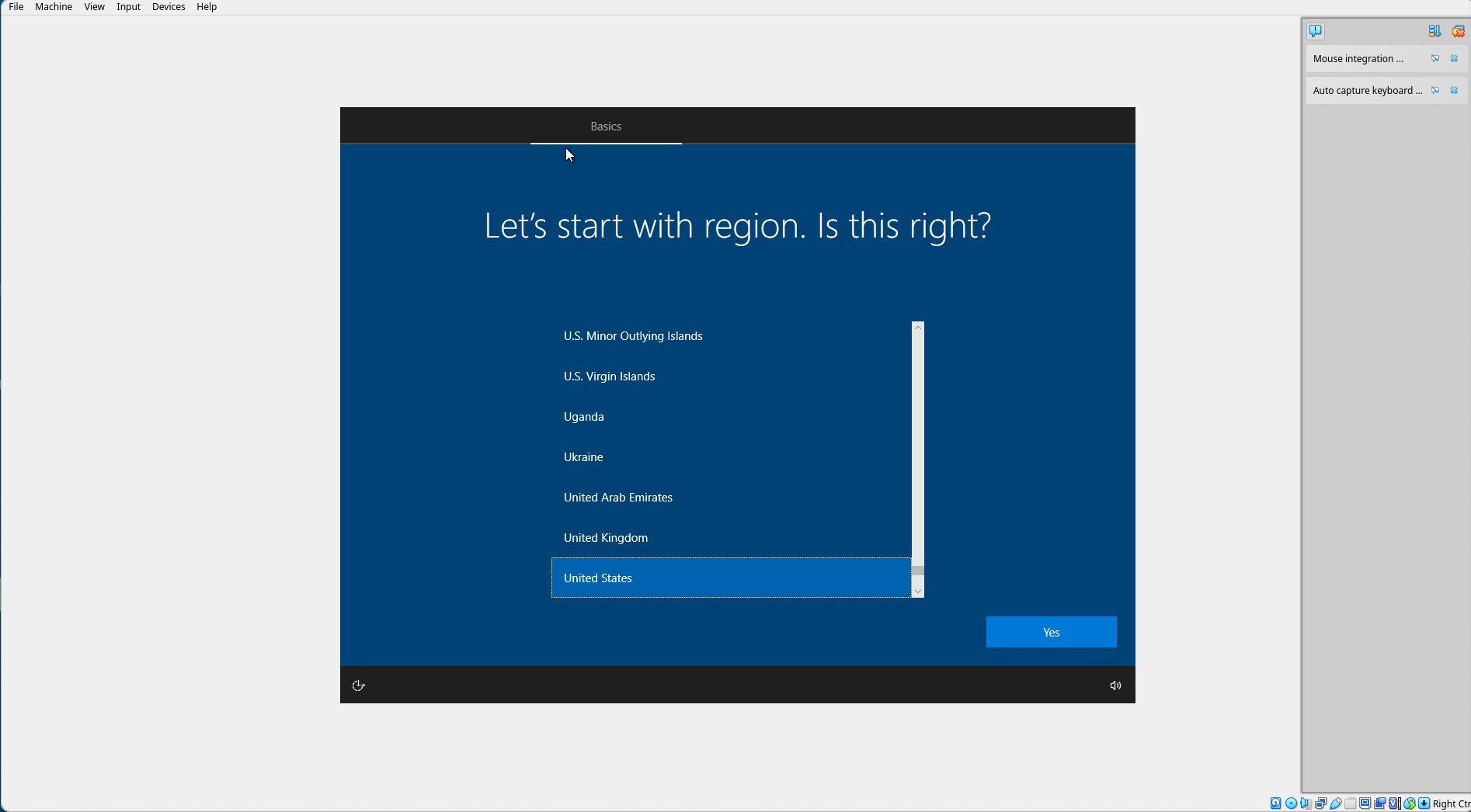
Select your region.
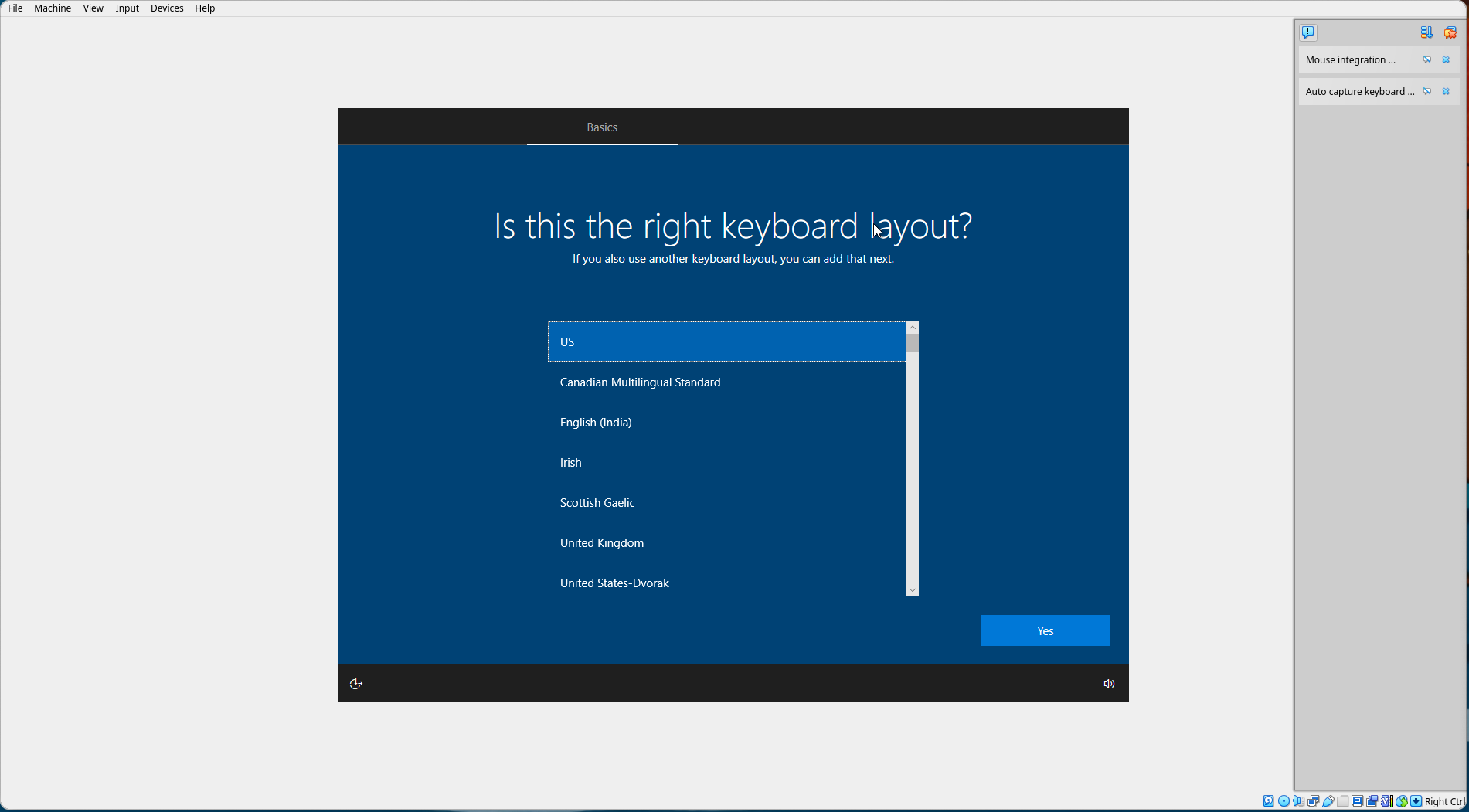
Select your keyboard layout.
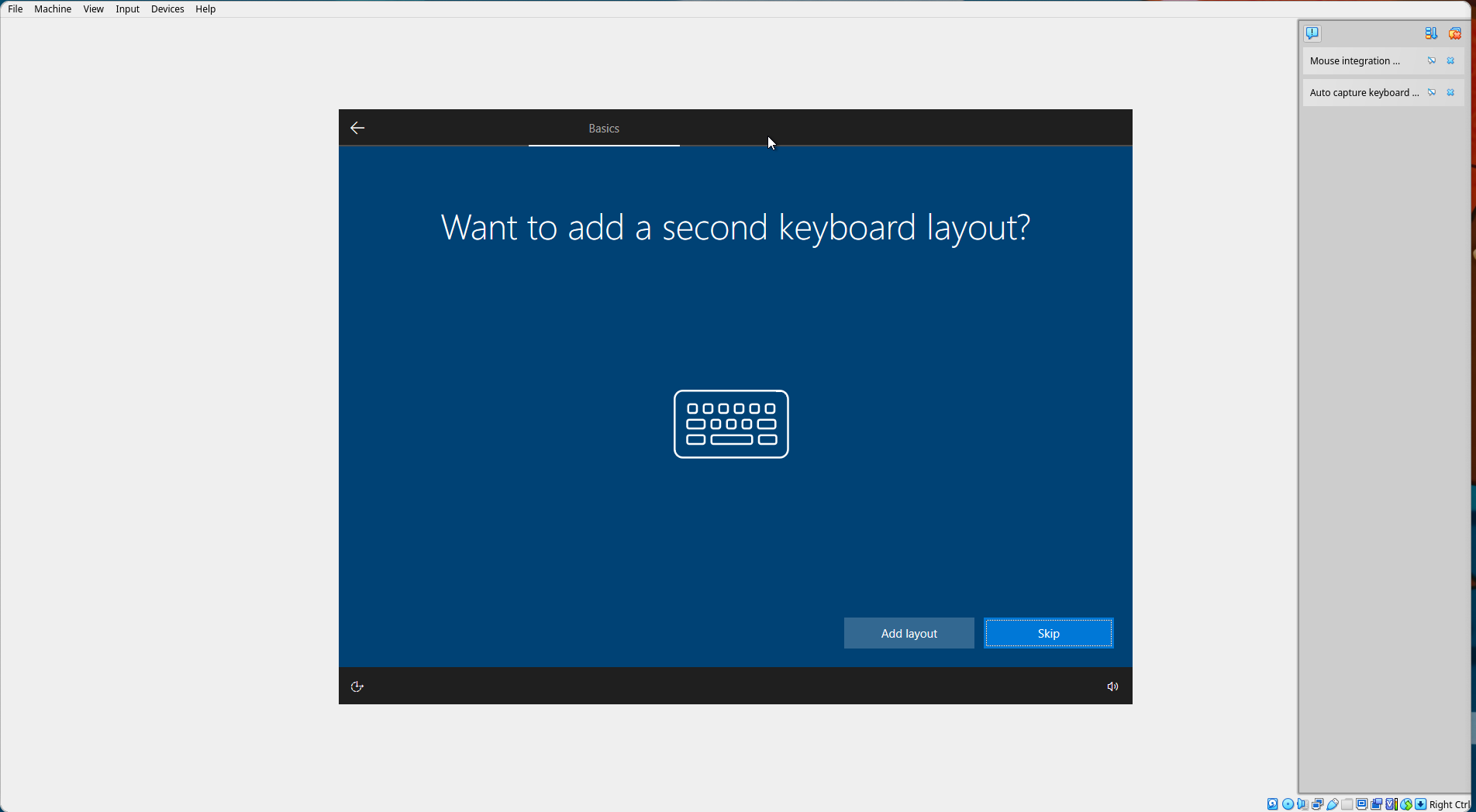
Skip adding a second keyboard layout.
Allow Windows to lie to you while it phones home.
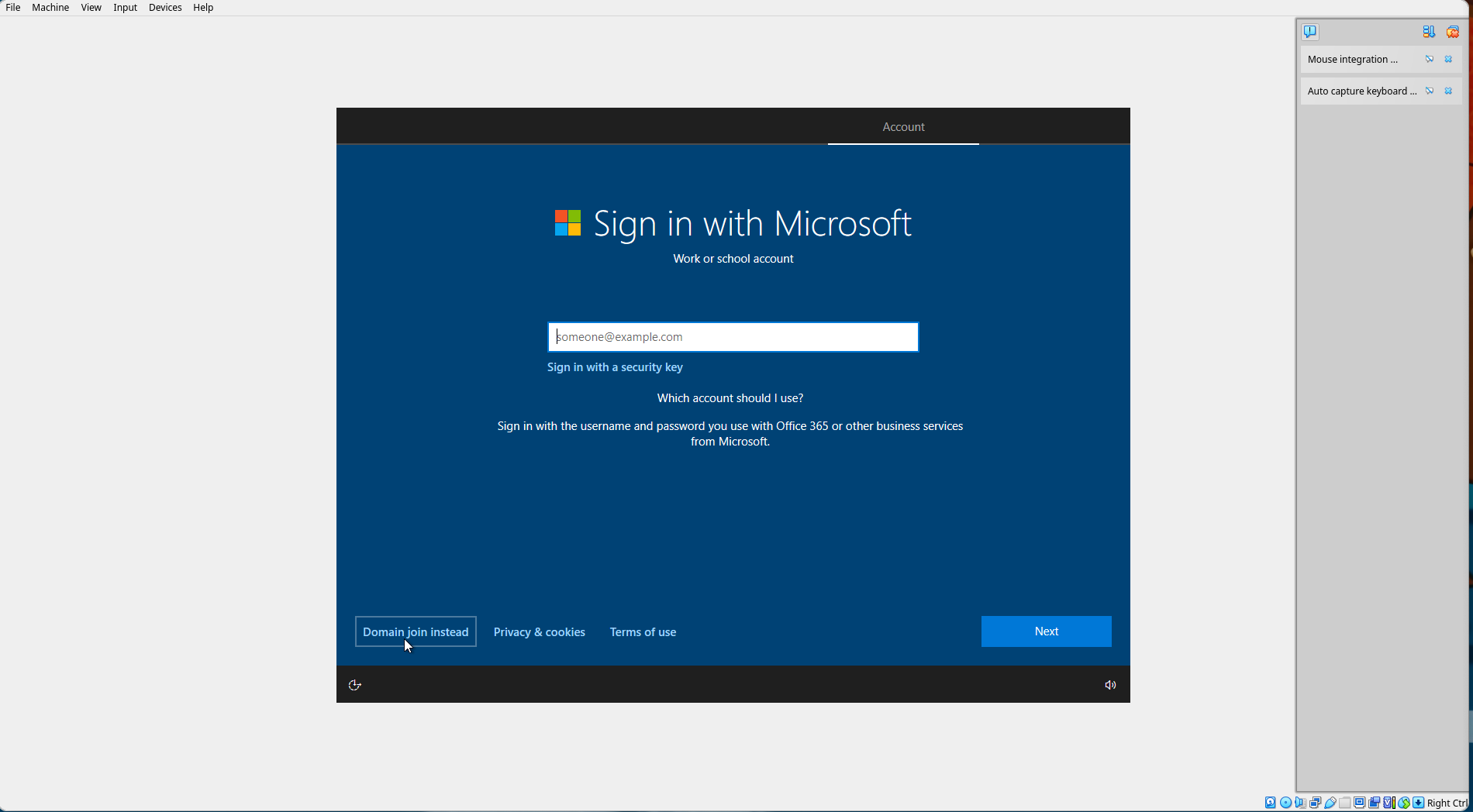
Select "Domain join instead".
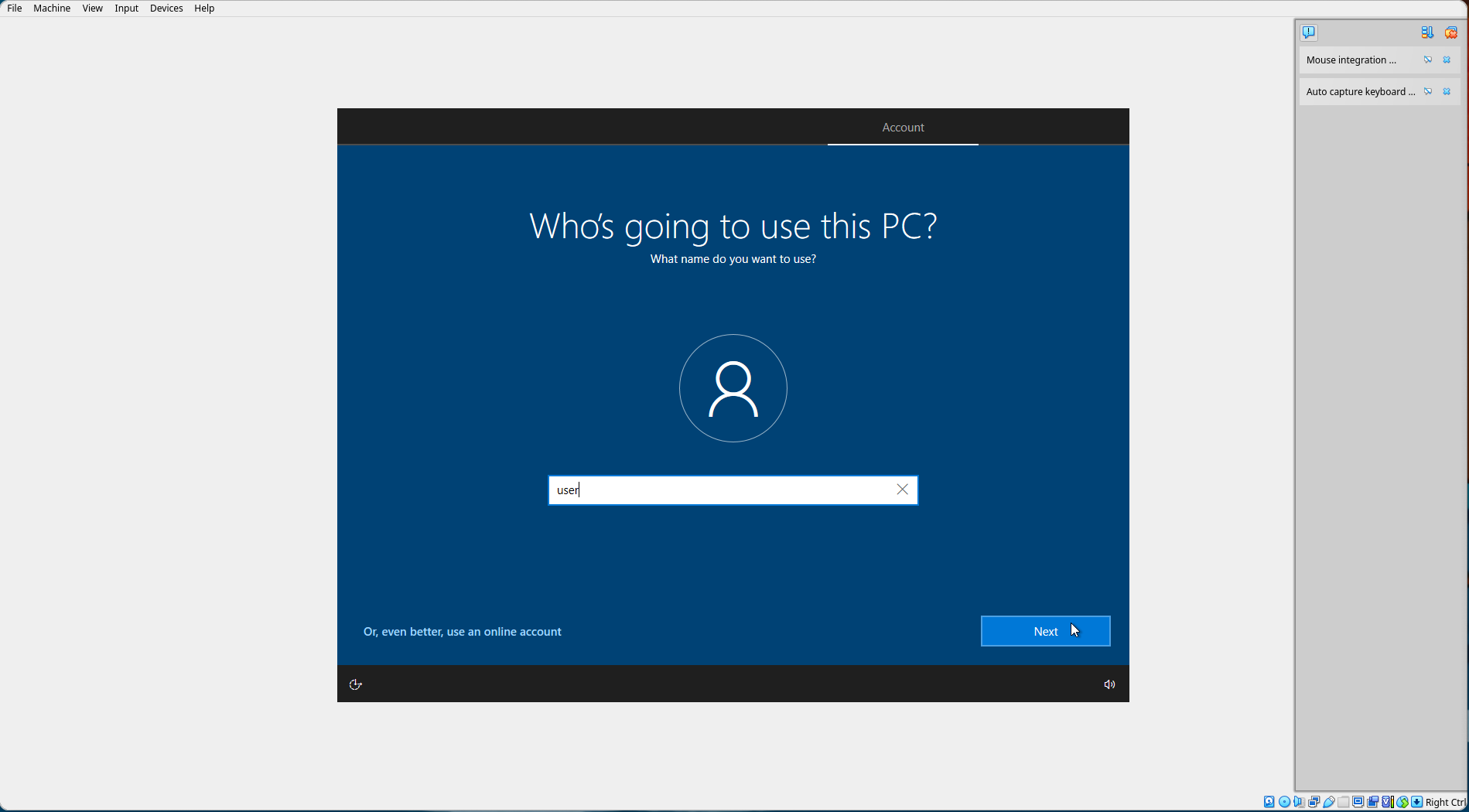
Set a username. For this tutorial, we'll use user. Select "Next".
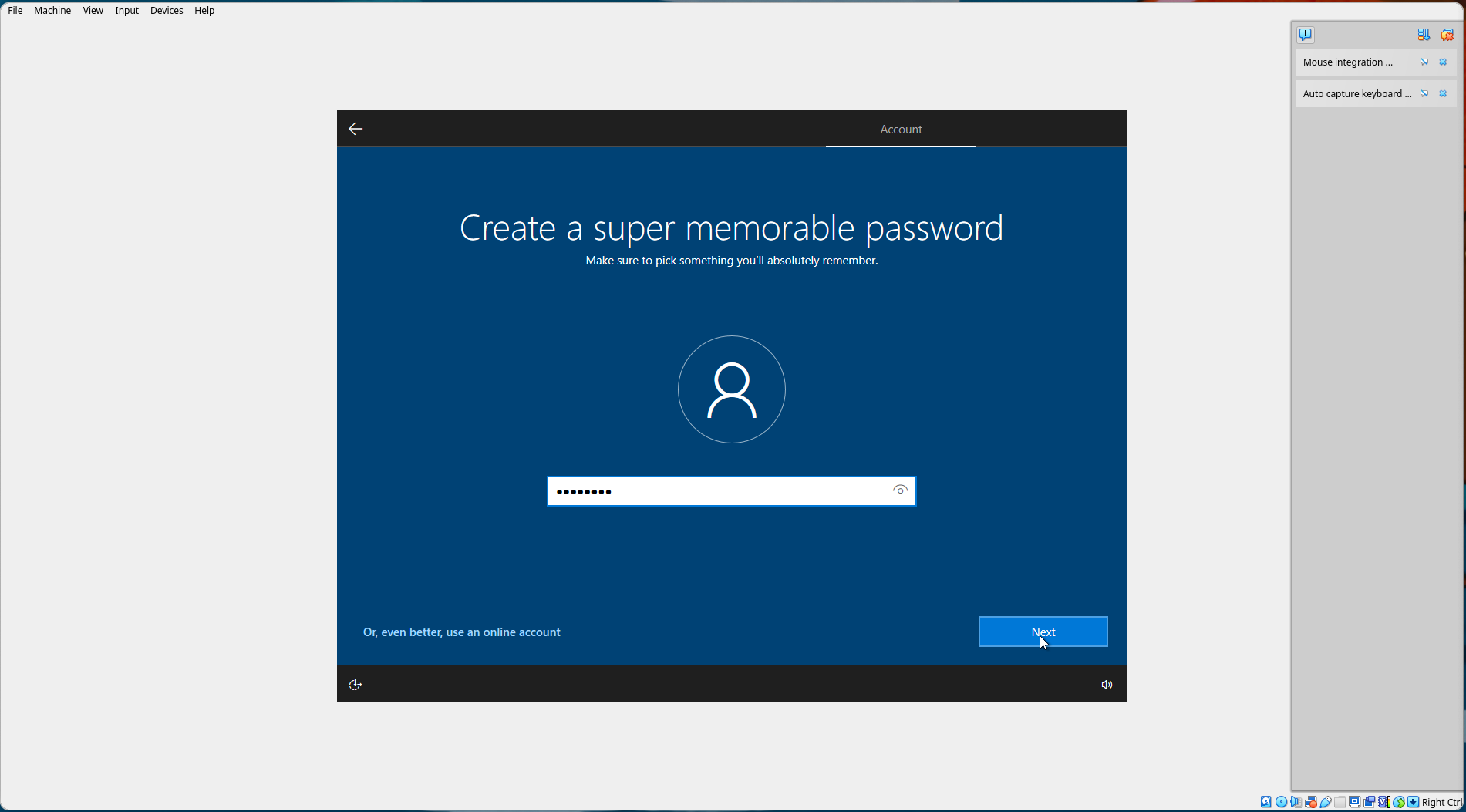
Set a password. For this tutorial, we'll use password. Select "Next".
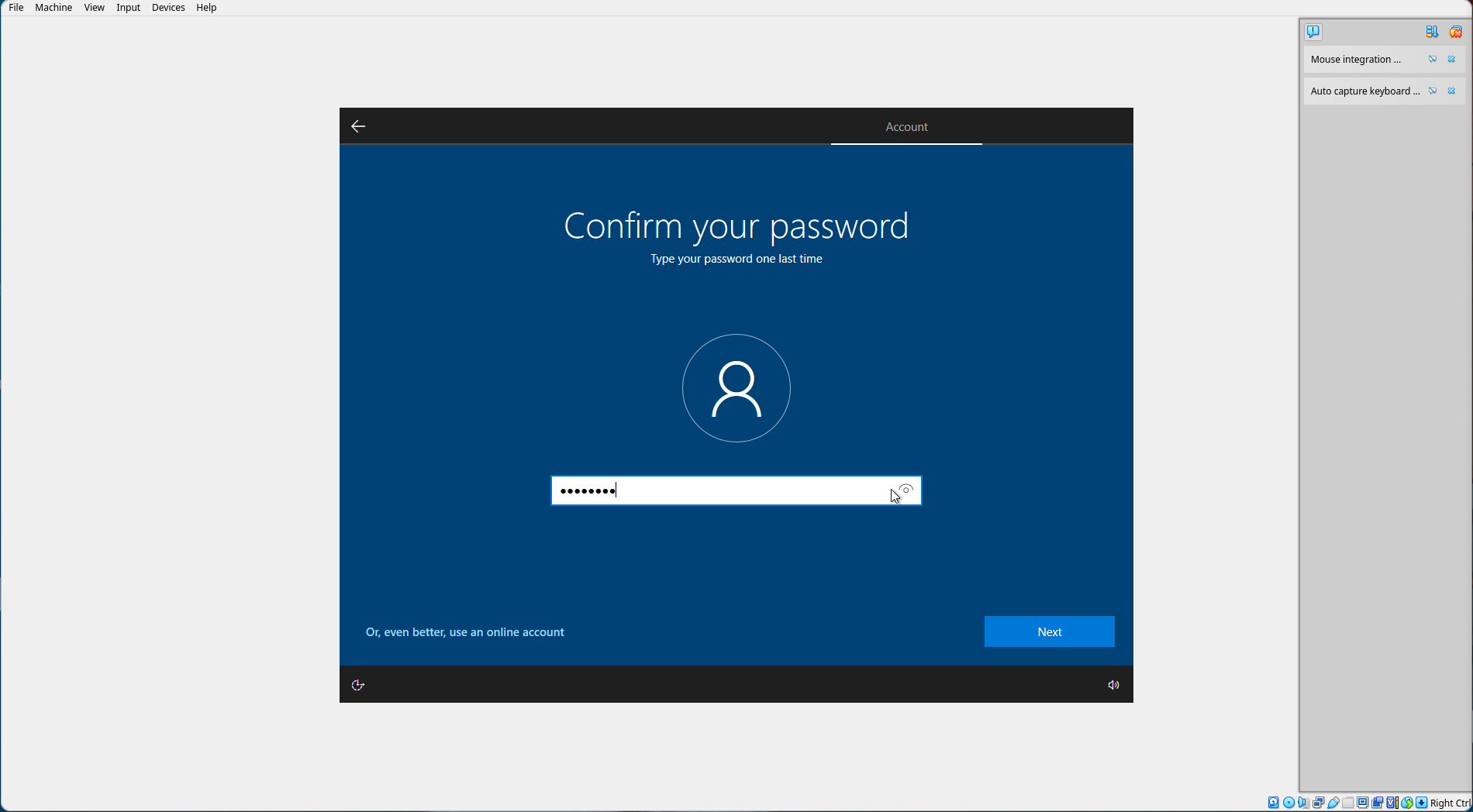
Confirm your password. Select "Next".
Our first dog's name was password. Select "Next".
Surprisingly, we were also born in the city of password. Select "Next".
This cannot possibly be a coincidence! Our childhood nickname was also password.
Select "Next".
Disable some of Microsoft's malware by checking "No" for all options. Then select "Accept".
Select "Not now".
Allow Microsoft to continue lying to you and wait until the install finishes.
Eventually, you'll be greeted with a clean desktop.
Set Up SSH
Click the Windows button and type "powershell". Then right click "Windows PowerShell" and select "Run as administrator".
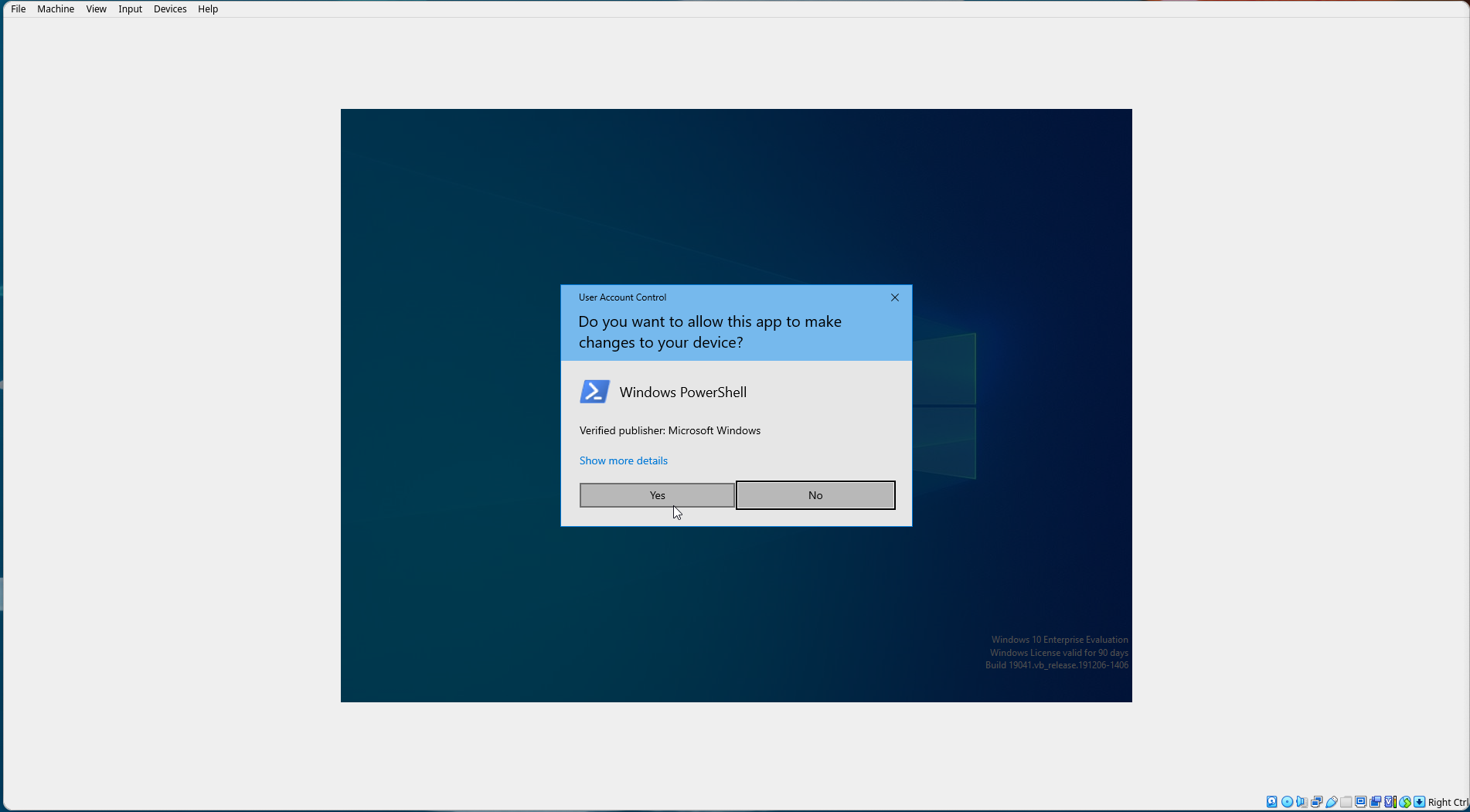
At the User Account Control (UAC) prompt, select "Yes".
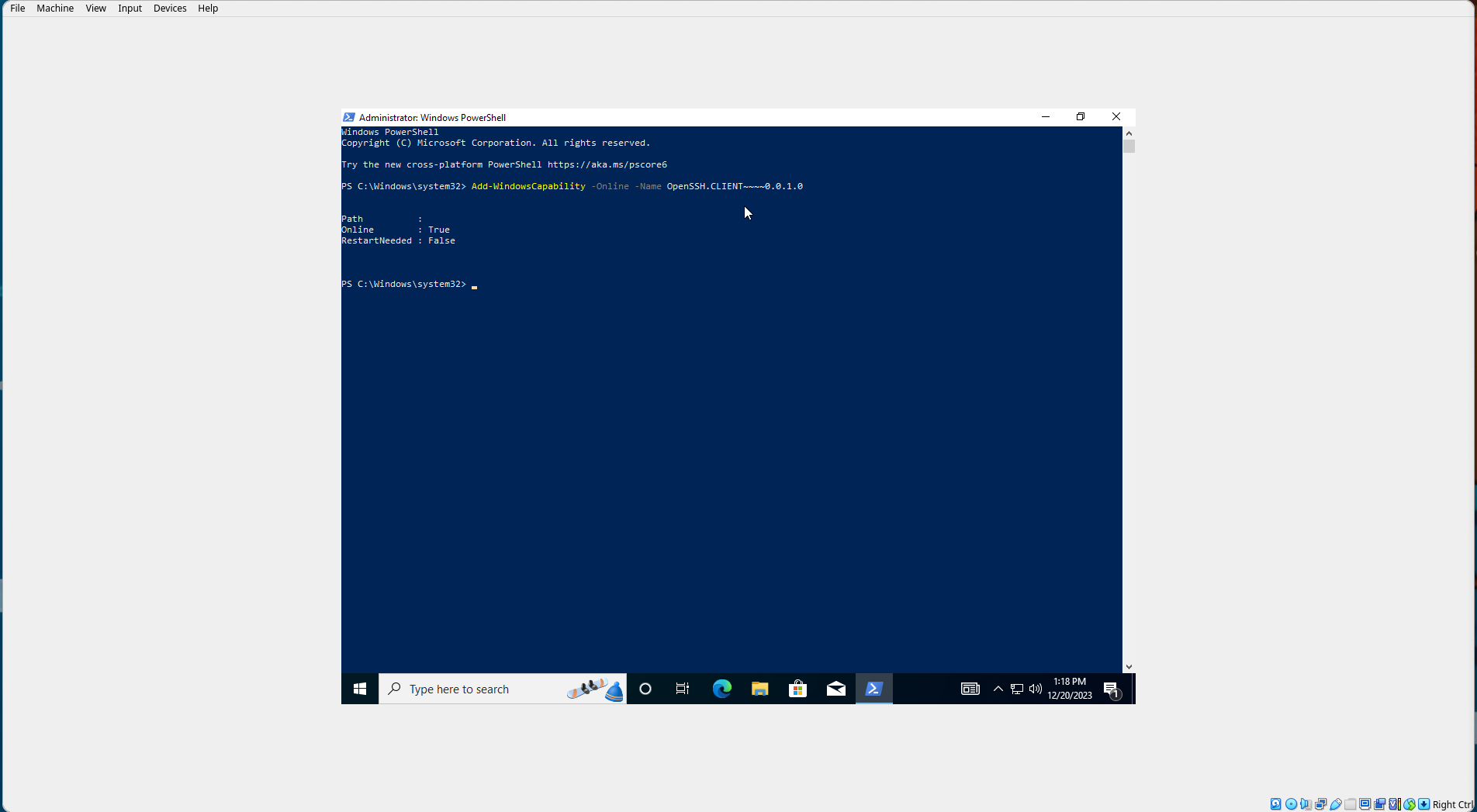
We will install and enable OpenSSH server as described in the Microsoft Documentation. In the PowerShell prompt, run:
Add-WindowsCapability -Online -name OpenSSH.CLIENT~~~~0.0.1.0
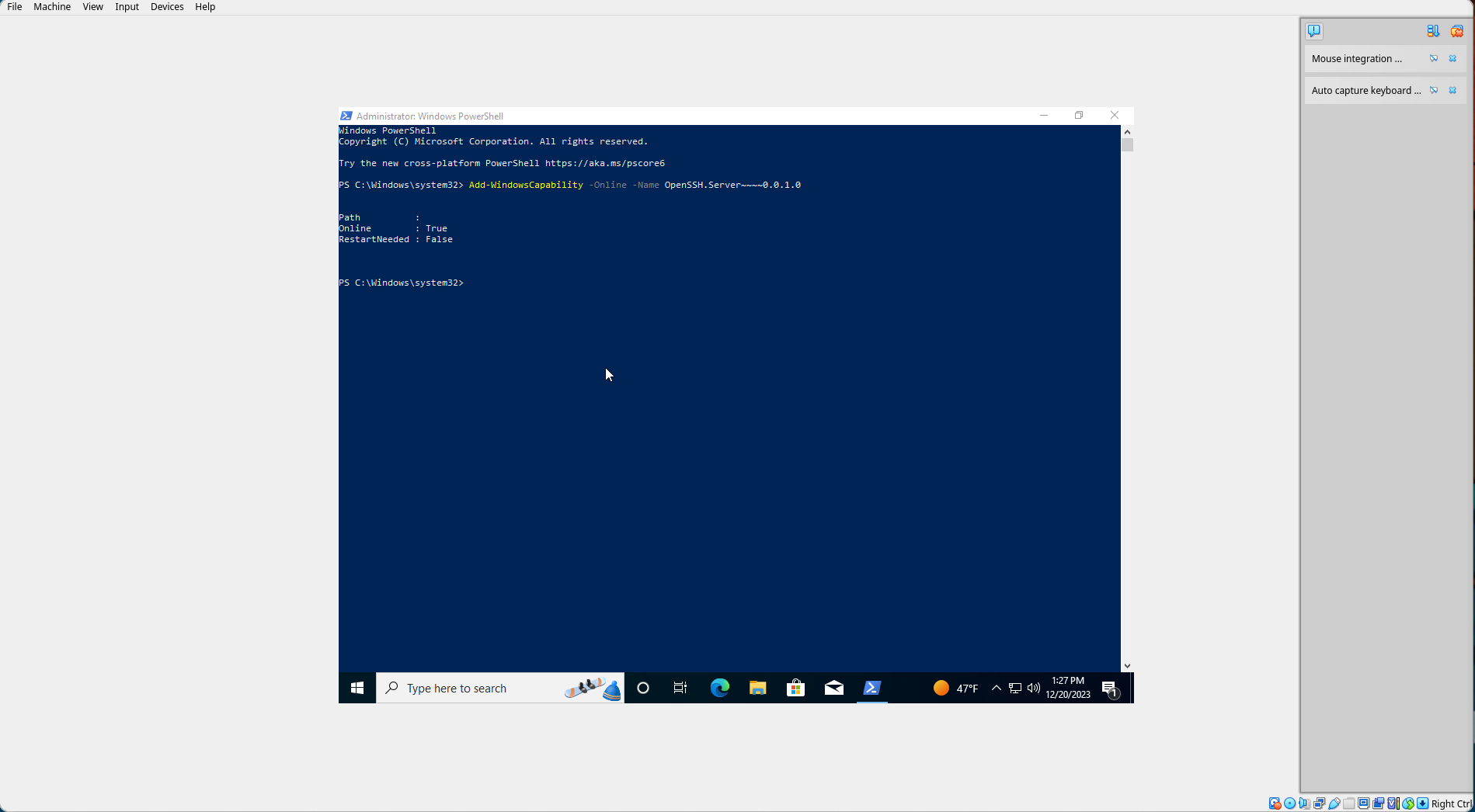
Next, in the PowerShell prompt, run:
Add-WindowsCapability -Online -name OpenSSH.Server~~~~0.0.1.0
Note that if this command fails with an error code, you may need to disconnect from any connected VPN/proxy on the host machine then restart the guest virtual machine, or set up the proxy on the guest virtual machine.
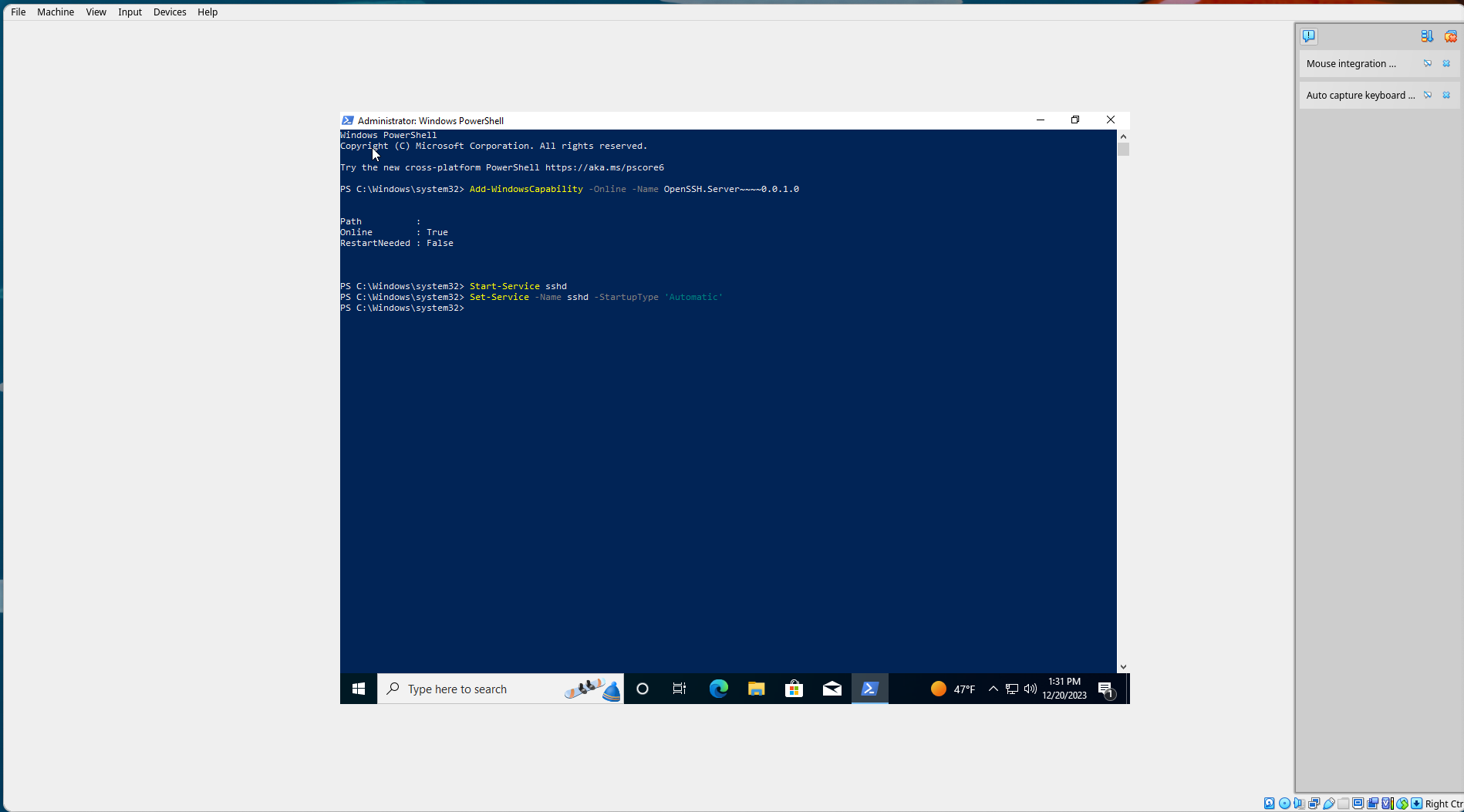
Then, run:
Start-Service sshd
Set-Service -name sshd -StartupType 'Automatic'
Enable SSH Port Forwarding in VirtualBox
In the VirtualBox menu bar, select Machine > Settings to open the machine settings.
Select the "Network" tab on the left.
Select the "Advanced" drop-down menu.
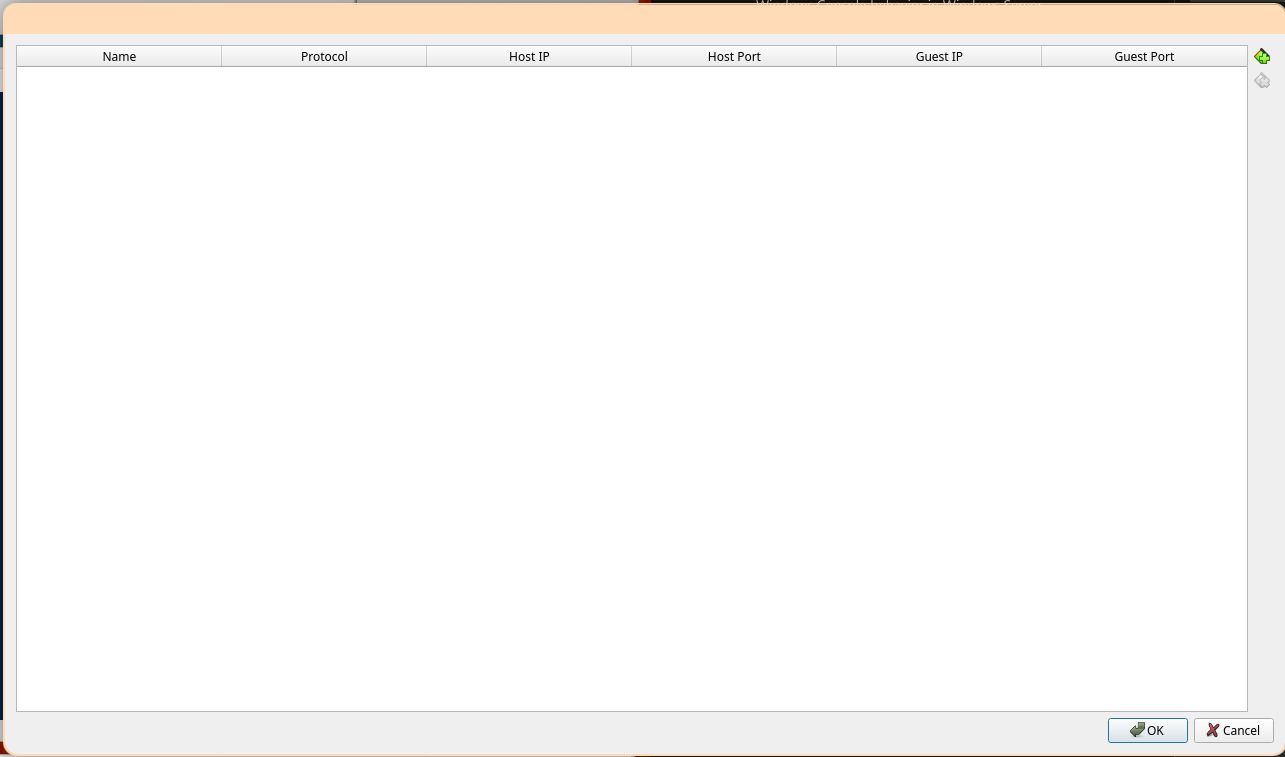
Select the "Port Forwarding" button to open the port forwarding menu.
Select the top-right button "Adds port forwarding rule" to add a new rule.
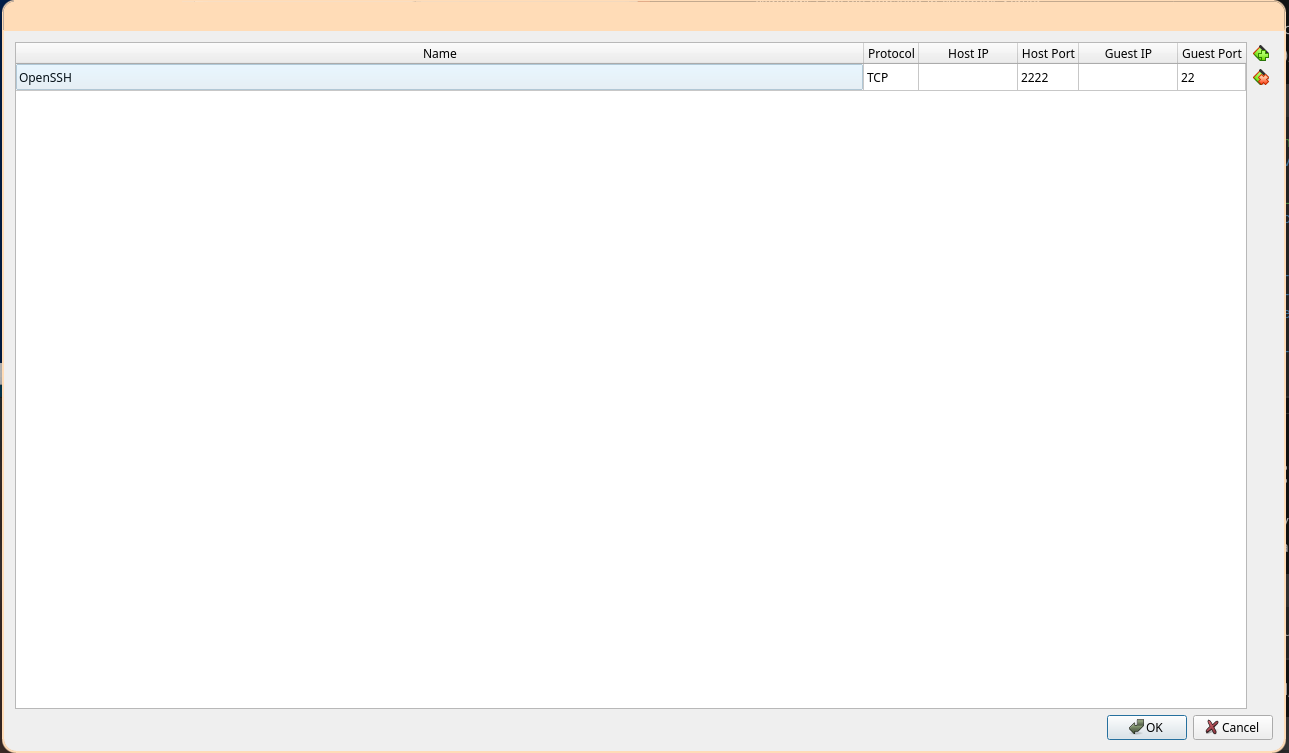
Add a forwarding rule called "OpenSSH" on protocol TCP from host port 2222 to guest port 22. Leave both IP fields blank. Select "OK" in the port forwarding menu, then select "OK" on the settings menu.
Then, on your host (if your host is a Windows machine, enable the OpenSSH.CLIENT capability on your host as shown above), run:
ssh -p 2222 user@localhost
After entering the password at the prompt, you should be greeted with a command prompt:
Microsoft Windows [Version 10.0.19045.2006]
(c) Microsoft Corporation. All rights reserved.
user@DESKTOP-E04G80I C:\Users\user>
Change Default Shell to PowerShell
This is a CMD command prompt. The remainder of the tutorials for Windows will provide only PowerShell commands. To change the default shell for OpenSSH to PowerShell, run:
powershell.exe -Command "New-ItemProperty -Path 'HKLM:\SOFTWARE\OpenSSH' -Name DefaultShell -Value 'C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe' -PropertyType String -Force"
Exiting the SSH session by running exit, then reconnecting with ssh -p 2222 user@localhost should log you into a PowerShell session by default:
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
Try the new cross-platform PowerShell https://aka.ms/pscore6
PS C:\Users\user>
Installing the EWDK
We will use the Enterprise Windows Driver Kit (EWDK) throughout this tutorial to compile both user-space applications and Windows Kernel modules.

We will use the EWDK because unfortunately all versions of Visual Studio (including Visual Studio Community) are not possible to easily install on the command line, which means more images which complicate a tutorial unnecessarily and make it harder to maintain.
Download the EWDK
If the link below becomes outdated, you can obtain the EWDK ISO download by visiting the WDK and EWDK download page and downloading it. The page Using the Enterprise WDK also contains useful background.
You can download the latest version of the EWDK as of the time of writing (20 December 2023) by running (note the first line is required to obtain a reasonable download speed):
$ProgressPreference = 'SilentlyContinue'
Invoke-WebRequest -Uri "https://software-static.download.prss.microsoft.com/dbazure/888969d5-f34g-4e03-ac9d-1f9786c66749/EWDK_ni_release_svc_prod1_22621_230929-18
00.iso" -OutFile ~/Downloads/EWDK_ni_release_svc_prod1_22621_230929-1800.iso
This download is quite large (approximately 15GB). The command will finish when the download is complete.
Mount the EWDK Disk Image
To ensure paths throughout the tutorial work correctly, we will mount our
disk image to a specific drive letter (W).
$diskImage = Mount-DiskImage -ImagePath C:\Users\user\Downloads\EWDK_ni_release_svc_prod1_22621_230929-1800.iso -NoDriveLetter
$volumeInfo = $diskImage | Get-Volume
mountvol W: $volumeInfo.UniqueId
Note that after a reboot or sleep, you may need to run this command again to re-mount the disk image.
Test the Build Environment
We can now launch the build environment by running:
W:\LaunchBuildEnv.cmd
Test that the build environment works as expected:
cl
You should see the output:
Microsoft (R) C/C++ Optimizing Compiler Version 19.31.31107 for x86
Copyright (C) Microsoft Corporation. All rights reserved.
usage: cl [ option... ] filename... [ /link linkoption... ]
Make sure to exit the cmd environment after using it and return to PowerShell:
exit
Installing Development Tools
We will install a couple of additional development tools.
Set Up Winget
Typically, winget will work correctly, but in many cases it does not. Run the command:
winget source update
If you see the following output (with the Cancelled message):
winget source update
Updating all sources...
Updating source: msstore...
Done
Updating source: winget...
0%
Cancelled
Then run the following to manually update the winget source:
Invoke-WebRequest -Uri https://cdn.winget.microsoft.com/cache/source.msix -OutFile ~/Downloads/source.msix
Add-AppxPackage ~/Downloads/source/msix
winget source update winget
You should now see the correct output:
Updating source: winget...
Done
Install Git
Install Git with:
winget install --id Git.Git -e --source winget
And add it to the path with:
[Environment]::SetEnvironmentVariable("Path", $env:Path + ";C:\Program Files\Git\bin", "Machine")
Install Vim
Install Vim with:
winget install --id vim.vim -e --source winget
And add it to the path with:
[Environment]::SetEnvironmentVariable("Path", $env:Path + ";C:\Program Files\Vim\vim90", "Machine")
Install CMake
Install CMake with:
winget install --id Kitware.CMake -e --source winget
And add it to the path with:
[Environment]::SetEnvironmentVariable("Path", $env:Path + ";C:\Program Files\CMake\bin", "Machine")
Install Visual Studio Community
We will use the EWDK to build the vulnerable driver, but because we will be using LibFuzzer to fuzz the driver from user-space, we also need to install Visual Studio Community with the proper workloads to obtain the LibFuzzer implementation.
winget install Microsoft.VisualStudio.2022.Community --silent --override "--wait --quiet --addProductLang En-us --add Microsoft.VisualStudio.Workload.NativeDesktop --add Microsoft.VisualStudio.Component.VC.ASAN --add Microsoft.VisualStudio.Component.VC.ATL --add Microsoft.VisualStudio.Component.VC.Tools.x86.x64 --add Microsoft.VisualStudio.Component.Windows11SDK.22621 --add Microsoft.Component.VC.Runtime.UCRTSDK --add Microsoft.VisualStudio.Workload.CoreEditor"
The command will return once the installation is complete.
Refresh PATH
The $env:Path environment variable changes will not take effect until SSHD is restarted. Restart it with (this will not end your current session):
Restart-Service -Name sshd
Now, exit the sesion by typing exit and re-connect via SSH. Confirm the
environment variable changes took effect:
git --version
vim --version
cmake --version
Both commands should succeed.